The goal of this homework is to practice writing regular expressions, with a little help from Steve Jobs! We will use Steve Jobs's Wikipedia entry for our test string.
PART 1: Jobs on Regex101 [30 points]
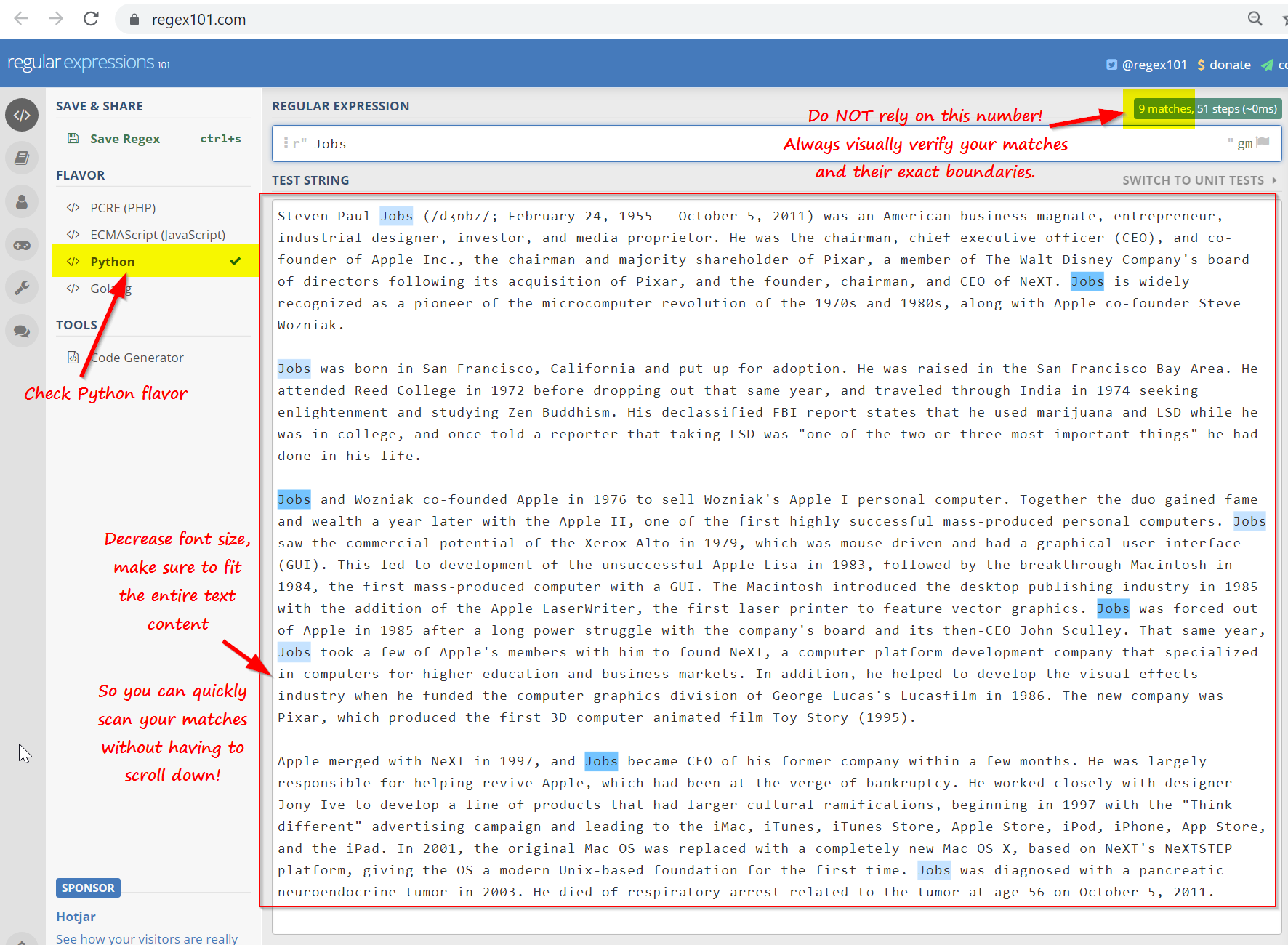
The goal of part 1 is to get you practice writing regular expressions on regex101. From the Jobs Wikipedia article, copy the first five paragraphs above the Early life section ('Steven Paul Jobs ... over 450 patents in total.[4]'), and paste into the text window of regex101. First, notes on using the site:
Choose the PCRE2 flavor of regex. (See Lecture14.pdf for further settings.)
Adjust the font size so all of the text fits in the window. That way, you can quickly scan your matches without having to scroll. (On Chrome, Control - zooms out.)
Match count is displayed on the top right corner. I've provided the correct match count for some questions, but don't just rely on it: you must visually inspect your matches to make sure they are legit, no true matches are getting left out, and match boundaries are correct.
Leave the gm flags turned on. And, do not use the "i" (case-insensitive) flag for PART 1.
Additional instructions:
Write down your answers in a MS Word document file. While not strictly necessary, I highly recommend including screenshots: they will be good for your own reference.
Is your match count different from mine? Perhaps you are wrong, perhaps the Wikipedia page has been edited in the meantime. Check this revision history page; my solution is based on Smuckola's edit made on October 17 05:29. Base your answers on this version.
10+ years after Jobs's death, there's still a feverish war raging on Wikipedia to claim his soul, as evidenced by the very frequent edits his page suffers. Some edits are downright trollish... why won't these people let us practice regex in peace! At any rate, do use the direct link to the correct version above.
About composing regular expressions:
Dealing with a small text, it is possible to write a trivial regular expression that simply lists all alternative forms separated by the "|" operator. DO NOT DO THIS. For example, for Q5, you can easily write /iMac|iTunes|iPod|iPhone|iPad/ and be done with it -- but the point is to write a more compact and elegant regular expression that captures the structure shared by the target strings.
On the flip side, do not over-pursue compacting of your expression. For example, /have|has|had/ can be further compacted to /ha(ve|s|d)/, but then you sacrifice readability for a small gain. You should try to strike a happy medium.
When it comes to finding words, make sure to match the whole words. When finding words ending with ing, don't just match the ing part! Your regex should match the entire words such as seeking.
That was it for the instructions, let's get to it! Write regular expressions matching the descriptions below. When the number of matches isn't given ("? matches"), answer how many matches you found.
Years. (21 matches)
Dates. (2 matches)
The word computer and its variations (capitalized and plural; exclude microcomputer but allow matching within hyphenated words such as computer-animated). (7 matches)
All-caps (all in uppercase) words. (9 matches)
Apple's product names, starting with 'i': iPod, iTunes, iPad, etc. (6 matches)
Words ending in -ing. (13 matches)
A word ending in -ly and the following word. (8 matches)
Words with possessive 's: Jobs's, etc. (3 matches)
Words that have x or X in them. (8 matches)
The indefinite article a and an. (? matches: answer how many you found)
Words that are 12 characters or longer. Do not count hyphens. (? matches)
Hyphenated words. (? matches)
Footnote numberings in a pair of square brackets []. Include [] in the matched substrings. (? matches)
Parenthesis enclosed in a pair of round brackets (). Include () so it matches (1995) as a whole. (? matches)
This one is in fact tricky to get right. You might want to look up how to counter "greedy matching behavior" of regular expression operators.
'the ... of' constructions. Allow '...' to be multiple words, up to 4. Intervening words may accompany punctuation/symbols. (? matches)
PART 2: Jobs on Python's re Library [10 points]
In this part, we will practice Python's re module using the Steve Jobs wikipedia article. In IDLE shell, start out by copying and pasting the same initial paragraphs, and then use the re.findall() method:
>>> jobs = """Steven Paul Jobs (February 24, 1955 – October 5, 2011) was an
American businessman, inventor, and investor best known for co-founding
...
Jobs holds over 450 patents in total.[4]""">>> re.findall(r'\d+', jobs)
['24', '1955', '5', '2011', '1970', '1980', '1955', '1972', '1974', '1976',
'1979', '1983', '1984', '1985', '1985', '1986', '3', '1995', '28', '1997',
'1999', '2002', '3', '2003', '2011', '2022', '141', '450', '4']
Then, complete each of the regex operations below. In your HW document, copy and paste screenshots showing each Python code and the shell output.
Using re.findall(), find all substrings that match all-caps words. (= Q4 of PART 1)
Find words ending in -ly along with the word after. (= Q7)
Find hyphenated words. (= Q12)
Find Parenthesis enclosed in a pair of round brackets (). See Q14 above for details.
Find 'the ... of' constructions. See Q15 above for details.
Remember to use re.IGNORECASE (= re.I) when appropriate. You might need to use it with flags= syntax: flags=re.I
If you are using () in your regular expression, be mindful about whether or not you want it to result in a group capture. Remember: you can avoid group capture by using (?:).
SUBMIT:
A document (MS Word doc, PDF, etc.) containing your answers.
{kind=link}