Daily To-do Assignments
To-do #1
Due 8/31 (Th)The Internet is full of published linguistic data sets. Let's data-surf! Instructions:
- Go out and find two linguistic data sets you like. One should be a corpus, the other should be some other format. They must be free and downloadable in full.
- You might want to start with various bookmark sites listed in the following Learning Resources sections: Linguistic Data, Open Access, Data Publishing and Corpus Linguistics. But don't be constrained by them.
- Download the data sets and poke around. Open up a file or two to take a peek.
- In a text file (should have .txt extension), make note of:
- The name of the data resource
- The author(s)
- The URL of the download page
- Its makeup: size, type of language, format, etc.
- License: whether it comes with one, and if so what kind?
- Anything else noteworthy about the data. A sentence or two will do.
- If you are comfortable with markdown, make an .md file instead of a text file.
To-do #2
Due 9/7 (Th)Learn about the numpy library: study the Python Data Science Handbook and the DataCamp tutorial. While doing so, create your own study notes, as a Jupyter Notebook file entitled numpy_notes_yourname.ipynb. Fill it with examples, explanations, etc. Replicating the DataCamp examples is also something you could do. You are essentially creating your own reference material.
SUBMISSION: Your file should be in the todo2/ directory of the Class-Practice-Repo. Push to your GitHub fork, and create a pull request for me.
To-do #3
Due 9/12 (Tue)Learn about the pandas library: study the Python Data Science Handbook and the DataCamp tutorial. While doing so, create your own study notes, as a Jupyter Notebook file entitled pandas_notes_yourname.ipynb. One more thing: find or create a good spreadsheet file (.csv, .tsv, etc.) and practice on it. Name the file xxxxx_yourname.csv, ...tsv, etc.
SUBMISSION: Your files should be in the todo3 directory of the Class-Practice-Repo. Push to your GitHub fork, and create a pull request for me.
To-do #4
Due 9/14 (Thu)This one is a continuation of To-do #3: work further on your study notes from To-do #3. Browse through the spreadsheet files submitted by your fellow classmates. Pick one, and try it out in your study notes. You are welcome to view the classmate's notebook to see how she/he did it.
Note: do not break your back on this To-do4! You should instead get started on upcoming Homework 2.
SUBMISSION: We'll stick to the todo3/ directory in Class-Practice-Repo. Push to your GitHub fork, and create a pull request for me.
To-do #5
Due 9/19 (Tue)You are making the ULTIMATE numpy + visualization notes this time. In todo5/ directory of Class-Practice-Repo, you will find all of your CSV files already copied over: feel free to use them in your code. In the directory, your notebook file should be named pandas_notes2_yourname.ipynb. Note "2" in there! Start with your previous pandas notebook, but make sure it now covers everything there is to know about pandas (OK, maybe not everything-everything, but you get the idea). And importantly, include some examples of visualization/plotting/graphing.
AND: Go get started on the upcoming Homework 2! It's due on Thursday, so this assignment is IN PERIOD.
SUBMISSION: Your files should be in the todo5 directory of the Class-Practice-Repo. Push to your GitHub fork, and create a pull request for me.
To-do #6
Due 9/26 (Tue)Homework 2 was rough! Let's have you polish it up. In your HW2-Repo directory, make a copy of your HW2 submission. You can name it hw2_narae_FINAL.ipynb or something like it. You should:
- Tighten up your code.
- Polish up the organization and presentation side.
- Learn from your classmates' solutions. Give a shout-out.
- Improve upon visualization: try another plot/graph.
To-do #7
Due 9/28 (Thu)Read the Gries & Newman article (linked here) in preparation of next week's class discussion. Then, let's collaborate on a shared document called A list of corpora and corpus-related tools.
- The Corpus-Resources GitHub repo belongs to all of us: we are all listed as a collaborator.
- That means all of us has full read and write access: in GitHub's lingo, we have 'push access'.
- Which means no need to fork; you should directly clone. After that, push and pull directly.
SUBMISSION: There is no formal submission process, because this one does not involve you issuing a pull request or anything like that. I will check on the repo later to see you have indeed made your contribution.
To-do #8
Due 10/05 (Thu)Let's try Twitter mining! On a tiny scale that is. This blog post Data Analysis using Twitter presents an easy-to-follow, step-by-step tutorial, so you should follow it along.
First, you will need to install the tweepy library:
- Best way to do this is through pip. A screenshot (click to enlarge):
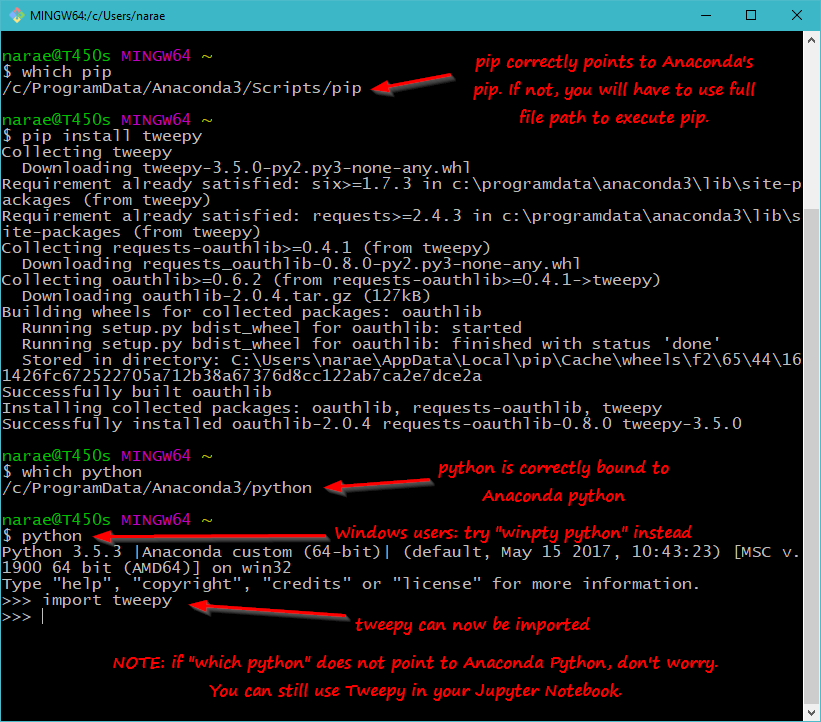
- If which pip does not show your Anaconda version of pip, it means you cannot simply go pip install tweepy. You will instead have to specify the complete path for Anaconda's pip. So, find your Anaconda installation path, and install Tweepy like so:
/c/ProgramData/Anaconda3/Scripts/pip install tweepy
Your pip path might be something like /c/Users/your-user-name/Anaconda3/.... You should use TAB completion while typing out the path. - If you are having trouble finding your Anaconda's path, try which -a python. The -a flag shows all python executables found in your path.
- If which python does not point to your Anaconda Python, don't worry about it. As long as installation went fine, you should be able to import tweepy and use it in your Jupyter Notebook.
- Obviously, if you don't have a Twitter account, you will have to create one first. And then, you should create an API account.
- This is exciting stuff, but don't go overboard! 100 Tweets are enough for this exercise. Overloading API without taking proper cautionary steps is a sure-fire way to get yourself banned from tech sites.
- You will be using your 'Consumer Key' and 'Consumer Secret' in your code. You should not be sharing them! I suggest you do your scripting work in some other directory, and when ready copy over the Jupyer Notebook file in the submission folder and change the string values to 'XXXXXXXXXXXXXX'.
To-do #9
Due 10/17 (Tue)Let's try sentiment analysis on movie reviews. Follow this tutorial in your own Jupyter Notebook file. Feel free to explore and make changes as you see fit. If you haven't already, watch DataCamp tutorials to give yourself a good grounding: Supervised Learning with scikit-learn, and NLP Fundamentals in Python.
Students who took LING 1330: compare sklearn's Naive Bayes with NLTK's treatment and include a blurb on your impression. (You don't have to run NLTK's code, unless you want to!)
SUBMISSION: Your jupyter Notebook file should be in the todo9 folder of Class-Practice-Repo. Push to your fork and create a pull request for me.
To-do #10
Due 11/7 (Tue)Let's have you visit classmates' term projects and take a look around. Steps:
- Create your own "visitor's log" file
in the todo10 directory of Class-Practice-Repo. It can be found here.Do this ASAP, so you don't keep your visitors waiting! Change of plan! Let's have you directly push your visitor's log entries, rather than me playing the gatekeeper. We will change the venue.
Change of plan! Let's have you directly push your visitor's log entries, rather than me playing the gatekeeper. We will change the venue.
- Remember the delightful "favorite animal" exercise? It was done through this repo where everyone had push access. The repo's name used to be 'Corpus-Resources', which is probably what it is still on your own laptop. We will use this repo.
- Inside, I created the the todo10_visitors_log directory for logging our visits.
- Since the repo's name changed, there are a few things you need to take care of on your laptop.
- First, change your directory name:
mv Corpus-Resources Shared-Repo - Your git setting still points to the old GitHub Repo's web address. You must update it:
git remote set-url origin https://github.com/Data-Science-for-Linguists/Shared-Repo.git - Pull from GitHub repo so you will have up-to-date files:
git pull
- First, change your directory name:
- Now this repo is ready! You have full push access, so no need to fork or create pull requests.
- You will be visiting two people ahead of you on this list. Margaret will be visiting Paige and Robert, Paige will be visiting Robert and Ryan, etc. Skip over folks who do not have a project repo.
- Visit their project repos. You don't need to download their code and run it at this time -- just browse their repo files.
- Then, log your visit on their visitor's log file. Enter two things:
- Something you learned from their project
- Something else that came to your mind. A helpful pointer, impressions, anything!
To-do #11
Due 11/9 (Thu)Let's have you poke at big data. Well, big-ish, from our point of view. The Yelp DataSet Challenge is now on its 10th round, where Yelp has kindly made their huge review dataset available for academic groups that participate in a data mining competition. Some important points before we begin:
- After downloading the data set, you should operate exclusively in a command-line environment, utilizing unix tools.
- I am supplying general instructions below, but you will have to fill in the blanks between steps, such as cd-ing into the right directory, invoking your Anaconda Python and finding the right file argument.
- You will be submitting a write-up as a Markdown file named todo11_yelp_yourname.md.
Let's download this beast and poke around.
- Download the JSON portion of the data, disregarding SQL and photos. It's 2.28GB compressed, and it took me about 25 minutes to download. You will need at least 9GB of disk space.
- Move the downloaded archive file into your Documents/Data_Science directory.
- From this point on, operate exclusively in command line.
- The file is in .tar format. Look it up if you are not familiar. Untar it using tar -xvf. I will create a directory called dataset with JSON files in it.
- How big are the files? Find out through ls -laFh.
- What do the data look like? Find out using head.
- How many reviews are there? Find out using wc -l.
- How many reviews use the word 'horrible'? Find out through grep and wc -l. Take a look at the first few through head | less. Do they seem to have high or low stars?
- How many reviews use the word 'scrumptious'? Do they seem to have high stars this time?
How much processing can our own puny personal computer handle? Let's find out.
- First, take stock of your computer hardware: disk space, memory, processor, and how old your system is.
- Create a Python script file: process_reviews.py. Content below. You can use nano, or you could use your favorite editor (atom, notepad++) provided that you launch the application through command line.
import pandas as pd import sys from collections import Counter filename = sys.argv[1] df = pd.read_json(filename, lines=True, encoding='utf-8') print(df.head(5)) wtoks = ' '.join(df['text']).split() wfreq = Counter(wtoks) print(wfreq.most_common(20))
- We are NOT going to run this on the whole review.json file! Start small by creating a tiny version consisting of the first 10 lines: head -10 review.json > FOO.json
- Then, run process_reviews.py on FOO.json. Note that the json file should be supplied as command-line argument to the Python script. Confirm it runs successfully.
- Next step, re-create FOO.json with incrementally larger total # of lines and re-run the Python script. The point is to find out how much data your system can reasonably handle. Could that be 1,000 lines? 100,000?
- While running this experiment, closely monitor the process on your machine. Windows users should use Task Manager, and Mac users should use Activity Monitor.
- Now that you have some sense of these large data files, write up a short reflection summary. What sorts of resources would it take to successfully process this dataset in its entirety and through more computationally demanding processes? What considerations are needed?
To-do #12
Due 11/16 (Thu)Another "visit your classmates" day! The same detail as before.
- You will be visiting two new people ahead of you on this list. Margaret will be visiting Ryan (whose first name is Andrew! Sorry!) and Alicia, Paige will be visiting Alicia and Ben, etc. Skip over folks who do not have a project repo.
- Visit their project repos. You don't need to download their code and run it at this time -- just browse their repo files.
- Then, log your visit on their visitor's log file found in the todo10_visitors_log directory of Shared-Repo. Enter two things:
- Something you learned from their project
- Something else that came to your mind. A helpful pointer, impressions, anything!
To-do #13
Due 11/21 (Tue)Yet another "visit your classmates" day! Two more people, ahead of you. You know the drill.