What should go in the blank so that the shown output is produced?
>>> for i in ? :
... print(i)
... here we go>>>
'here we go'
'here we go'.split()
['here', 'we', 'go']
['here we go']
Note the type difference: a. is a string, while the rest are all a list, including d. which is a list consisting of a single string. for x in y behaves differently depending on the type of y. When y is a string, x iterates through all characters in y. When y is a list, x iterates through individual items in it.
Below, we have a list of lists. What's the output?
Indexing can be stacked, as long as there is a sequence to be indexed. Here, subjects[2] has the value of 'linguistics', therefore subjects[2][3] is equivalent to 'linguistics'[3].
What goes in ① below? Pick all that fit.
>>> sent = ['It', 'was', 'a', 'dark', 'and', 'stormy', 'night']
>>> sent[2]
'a'>>> ① 'and'>>> sent[2:5]
['a', 'dark', 'and']>>> sent[3:]
['dark', 'and', 'stormy', 'night']>>> ② ['It', 'was', 'a']
sent[5]
sent[4]
sent[-3]
sent[4:5]
[CONTINUED] What goes in ② in the session above? Pick all that fit.
sent[0:3]
sent[:-4]
sent[:2]
sent[:3]
The script below contains a user-defined function. Once you execute it, you can call the function with an argument, as shown. What is the printed output in the shell?
def hasE(word):
ecount = word.count('E') + word.count('e')
if ecount == 0:
print(word, 'does not have any e.')
else:
print(word, 'has an e.')
foo.py
[CONTINUED] You execute the same function hasE() in a different way, like shown below. Then you probe the variable result. What are the outputs in ① and ②?
>>> result = hasE('HELLO')
...something happens... >>> print(result)
① >>> type(result)
②
Below is another user-defined function, this time a "returning" kind. For fun, you are feeding a returned output from the function right back into it. What's the output?
>>> def ahoyfy(word):
..."Returns a word with 'o' replaced by '-ahoy-'."... return word.replace('o', '-ahoy-')
...>>> ahoyfy('cola')
'c-ahoy-la'>>> ahoyfy('sophomore')
's-ahoy-ph-ahoy-m-ahoy-re'>>> ahoyfy(ahoyfy('Honolulu'))
?? >>>
[CONTINUED] You execute the same function ahoyfy() in a different way, like shown below. Then you probe the variable result. What are the outputs in ① and ②?
>>> result = ahoyfy('sophomore')
>>> print(result)
① >>> type(result)
②
Below, we have successfully added an item to a list. What is the command used?
>>> li = ['penguin', 'fox', 'owl', 'panda']
>>> ?? >>> li
['penguin', 'fox', 'owl', 'panda', 'elephant']>>>
li.add('elephant')
li.extend('elephant')
li += 'elephant'
li.append('elephant')
.extend() and += are normally used to add a *list* of new items to an existing list. That is why, upon seeing 'elephant', Python was forced to interpret it as a list... of letters! If it seems all too complicated, just remember: when adding a single item into a list, .append() is what you want.
Below, we are concatenating two lists. What is the command used?
Nothing: the shell quietly goes back to the prompt.
KeyError: ...
[CONTINUED] On the same dictionary plu, which of the following for loops produces the shown shell output? Pick all. (NOTE: your lines might be ordered differently -- dictionary keys do not have an inherent order.)
>>> one mouse two miceone goose two geeseone child two childrenone tooth two teeth>>>
a.
for k in plu:
print('one', k, 'two', plu[k])
b.
for k in plu.keys():
print('one', k, 'two', plu[k])
c.
for k in plu.values():
print('one', k, 'two', plu[k])
d.
for (k, v) in plu.items():
print('one', k, 'two', v)
[CONTINUED] Again operating on the dictionary plu, how do you get the following, alphabetically sorted, output? (There are a couple short solutions to this. One is just 11 characters!)
>>> ?? ['child', 'goose', 'mouse', 'tooth']>>>
Compose a function called areAnagrams(word1, word2). It takes two arguments word1 and word2, and returns True/False on whether they are anagrams of each other. An anagram is a word formed by rearranging the letters of a different word. Examples: 'cat' and 'act', 'state' and 'taste'. When executed, it should work like this:
>>> def areAnagrams(word1, word2):
... "Tests whether word1 and word2 are anagrams of each other"... ... ?? ... >>> areAnagrams('cat', 'panda')
False>>> areAnagrams('night', 'thing')
True>>>
The solution is very simple when using a right built-in function. To submit, copy-and-paste the function in its entirety (i.e. including the def ... line at the top). This question won't be auto-graded.
You wonder what attributes and methods are available for your string-type variable myword, so you call the built-in function dir() on it. Among the output (first few lines omitted here), you are curious about the isupper method, so you decide to print out the help message using help(). How is the command formulated? Two correct answers.
>>> myword = 'Hello'>>> dir(myword)
[ ...
'_formatter_parser', 'capitalize', 'center', 'count', 'decode', 'encode',
'endswith', 'expandtabs', 'find', 'format', 'index', 'isalnum', 'isalpha',
'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust',
'lower', 'lstrip', 'partition', 'replace', 'rfind', 'rindex', 'rjust',
'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith',
'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']>>> ?? Help on built-in function isupper:
isupper(...)
S.isupper() -> bool
Return True if all cased characters in S are uppercase and there is
at least one cased character in S, False otherwise.
>>> myword.isupper()
False
help(isupper)
help(myword.isupper)
help(myword.isupper())
help(str.isupper)
help(str.isupper())
Below, we want to affix '$' in front of the dollar amount before printing it out. What is the exact formulation of the print function that accomplishes this?
>>> monthly = 7000
>>> monthly * 12
84000>>> print( ?? )
Homer makes $84000 a year.>>>
'Homer makes', '$', monthly*12, 'a year.'
'Homer makes', '$'+(monthly*12), 'a year.'
'Homer makes', '$'+str(monthly*12), 'a year.'
'Homer makes', '$monthly*12', 'a year.'
As it is, monthly*12 (value: 84000) is an integer and therefore cannot be concatenated with a string '$'. You need to first convert it into a string.
A set is an orderless collection of distinct objects. In Python, set as a data type is marked with curly braces {}. set() as a function turns any sequence-type object into a set. Which of the following evaluates to False?
Sets cannot have duplicate members, therefore {1,2,3,3,3} is equivalent to {1,2,3}. What looks like duplicates are quietly ignored.
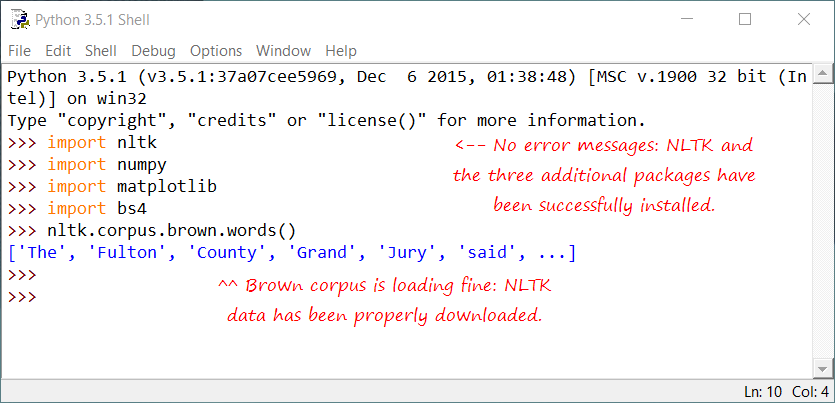
Install NLTK and NLTK data (instructions here), and upload a screenshot of your successful setup (like this one). If you run into trouble (many do), ask help on MS Teams.
PART 2: Pig Latin [10 points]
Pig Latin is a language game where each word is transformed as follows:
Basically, the onset of the initial syllable (which is the word-initial consonant or consonant cluster) is moved to the end of the string, and then 'ay' is suffixed. For words that begin with a vowel sound, 'way' is suffixed.
Your job is to finish this template script. When completed, the whole script, named pig_latin.py, works as a Pig Latin translator:
================== RESTART: pig_latin.py =============
Welcome to Pig Latin translator.Give me a sentence: We love school.
Your Pig Latin sentence is:
"Eway ovelay oolschay.">>>
================== RESTART: pig_latin.py =============
Welcome to Pig Latin translator.Give me a sentence: Colorless green ideas sleep furiously.
Your Pig Latin sentence is:
"Olorlesscay eengray ideasway eepslay uriouslyfay.">>>
The script operates on a few key functions. The pigLatinWord() function translates a single word into its Pig Latin counterpart, and it relies on two functions getInitialCs() and getTheRest(). It should work like this:
The pigLatinSent(), on the other hand, works on sentential input. Under the hood, it has to translate each word: it first tokenizes the sentence string into a list of words, then applies pigLatinWord() to each of them. It gathers up the translated words in a new list called tran, which it converts back into a string via .join() before returning. It also properly capitalizes the first letter of the sentence, and put a period at the end. (You may disregard all other punctuation.) It is currently set up to return the exact same string as the input; you should modify it so it works exactly like:
>>> pigLatinSent('We love school.')
'Eway ovelay oolschay.'>>> pigLatinSent('Linguistics is hard.')
'Inguisticslay isway ardhay.'>>>
When developing this script, start with getTheRest() and build up. You can/should directly execute individual functions in IDLE shell following an execution of the script. Note that the main routine ("Welcome to... Give me a sentence:...") is there merely as a user interface, and it's best to ignore it while you are actively implementing the functions. New programmers will be tempted to use it as a testing tool during development, but you should instead use the pigLatinSent() function for testing, which is much quicker. And finally: remember to CODE IN SHELL.
{kind=link}