Release 8.0
A58233-01
Library |
Product |
Contents |
Index |
| Pro*C/C++ Precompiler Programmer's Guide Release 8.0 A58233-01 |
|
![]()
![]()
This chapter presents advanced techniques in Pro*C/C++. Topics are:
Although the widely-used 7- or 8-bit ASCII and EBCDIC character sets are adequate to represent the Roman alphabet, some Asian languages, such as Japanese, contain thousands of characters. These languages can require at least 16 bits (two bytes) to represent each character. How does Oracle8 deal with such dissimilar languages?
Oracle8 provides National Language Support (NLS), which lets you process single-byte and multi-byte character data and convert between character sets. It also lets your applications run in different language environments. With NLS, number and date formats adapt automatically to the language conventions specified for a user session. Thus, NLS allows users around the world to interact with Oracle8 in their native languages.
You control the operation of language-dependent features by specifying various NLS parameters. Default values for these parameters can be set in the Oracle8 initialization file. Table 4-1 shows what each NLS parameter specifies.
The main parameters are NLS_LANGUAGE and NLS_TERRITORY. NLS_LANGUAGE specifies the default values for language-dependent features, which include
NLS_TERRITORY specifies the default values for territory-dependent features, which include
You can control the operation of language-dependent NLS features for a user session by specifying the parameter NLS_LANG as follows:
NLS_LANG = <language>_<territory>.<character set>
where language specifies the value of NLS_LANGUAGE for the user session, territory specifies the value of NLS_TERRITORY, and character set specifies the encoding scheme used for the terminal. An encoding scheme (usually called a character set or code page) is a range of numeric codes that corresponds to the set of characters a terminal can display. It also includes codes that control communication with the terminal.
You define NLS_LANG as an environment variable (or the equivalent on your system). For example, on UNIX using the C shell, you might define NLS_LANG as follows:
setenv NLS_LANG French_France.WE8ISO8859P1
During an Oracle8 database session you can change the values of NLS parameters. Use the ALTER SESSION statement as follows:
ALTER SESSION SET <nls_parameter> = <value>
The Pro*C/C++ Precompiler fully supports all the NLS features that allow your applications to process foreign-language data stored in an Oracle8 database. For example, you can declare foreign-language character variables and pass them to string functions such as INSTRB, LENGTHB, and SUBSTRB. These functions have the same syntax as the INSTR, LENGTH, and SUBSTR functions, respectively, but operate on a per-byte basis rather than a per-character basis.
You can use the functions NLS_INITCAP, NLS_LOWER, and NLS_UPPER to handle special instances of case conversion. And, you can use the function NLSSORT to specify WHERE-clause comparisons based on linguistic rather than binary ordering. You can even pass NLS parameters to the TO_CHAR, TO_DATE, and TO_NUMBER functions. For more information about NLS, see Oracle8 Application Developer's Guide.
Two internal database datatypes are for multi-byte character data. They are NCHAR and NVARCHAR2 (also known as NCHAR VARYING). You use these datatypes only in relational columns. Pro*C/C++ supported multi-byte NCHAR host variables in earlier releases, with slightly different semantics.
When you set the command-line option NLS_LOCAL to YES, multi-byte support with earlier semantics will be provided by SQLLIB (the letter "N" is stripped from the quoted string), as in Oracle7. SQLLIB provides blank padding and stripping, sets indicator variables, etc.
If you set NLS_LOCAL to NO (the default), Oracle8 supports multi-byte strings with the new semantics (the letter "N" will be concatenated in front of the quoted string). The database, rather than SQLLIB provides blank padding and stripping, and setting of indicator variables. Use NLS_LOCAL=NO for all new applications.
You specify which host variables hold National Character Set data. You insert the clause "CHARACTER SET [IS] NCHAR_CS" in character variable declarations. Then you are able to store National Character Set data in those variables. You can omit the token IS. NCHAR_CS is the name of the National Character Set.
For example:
char character set is nchar_cs *str = "<Japanese_string>";
In this example, <Japanese_string> consists of double-byte characters which are in the National Character Set JA16EUCFIXED, as defined by the variable NLS_NCHAR.
You can accomplish the same thing by entering NLS_CHAR=str on the command line, and coding in your application:
char *str = "<Japanese_string>"
Pro*C/C++ treats variables declared this way as of the character set specified by the environment variable NLS_NCHAR. The variable size of an NCHAR variable is specified as a byte count, the same way that ordinary C variables are.
To select data into str, use the following simple query:
EXEC SQL SELECT ENAME INTO :str FROM EMP WHERE DEPT = n'<Japanese_string1>';
Or, you can use str in the following SELECT:
EXEC SQL SELECT DEPT INTO :dept FROM DEPT_TAB WHERE ENAME = :str;
You set the environment variable NLS_NCHAR to specify a client-side (database) National character Set. When NLS_LOCAL=NO, the database supports NCHAR, if you have set a valid National Character Set with the precompiler option NLS_NCHAR.
NLS_NCHAR must have a valid character set specification (not a language name, that is set by NLS_LANG) at both precompile-time and runtime. SQLLIB performs a runtime check when the first SQL statement is executed. If the precompile-time and runtime character sets are different, SQLLIB will return an error code.
You can override the default assignments by equivalencing host variables to Oracle8 external datatypes, using the EXEC SQL VAR statement. This is called host variable equivalencing.
The EXEC SQL VAR statement can have an optional clause: CONVBUFSZ (<size>). You specify the size, <size>, in bytes, of the buffer in the Oracle8 runtime library used to perform conversion of the specified host variable between character sets.
The new syntax is:
EXEC SQL VAR <id> is <datatype> [CONVBUFSZ [IS] (<size>)] ;
or
EXEC SQL VAR <id> [cONVBUFSZ [IS] (<size>)];
where <datatype> is:
<SQL datatype> [ ( {<length> | <precision>, <scale> } ) ]
where:
There must be at least one of the two clauses, or both. The EXEC SQL VAR statement cannot be used with NCHAR variables.
Note that <size>, <length>, <precision> and <scale> can be any arbitrarily complex C constant expression whose value is known when the precompiler is run.
For example:
#define LENGTH 10 ... char ename[LENGTH+1]; exec sql var ename is string(LENGTH+1) convbufsz is (LENGTH*2);
Note also that macros are permitted in this statement.
When you have not used the CONVBUFSZ clause, the Oracle8 runtime automatically determines a buffer size based on the ratio of the host variable character size (determined by NLS_LANG) and the character size of the database character set. This can sometimes result in the creation of a buffer of LONG size. Database tables are allowed to have only one LONG column. An error is raised if there is more than one LONG value.
To avoid such errors, you use a length shorter than the size of a LONG. If a character set conversion results in a value longer than the length specified by CONVBUFSZ, then an error is returned at runtime. For a syntax diagram of this statement, see "VAR (Oracle Embedded SQL Directive)" on page -75.
A multi-byte character string in an embedded SQL statement consists of a character literal that identifies the string as multi-byte, immediately followed by the string. The string is enclosed in the usual single quotes.
For example, an embedded SQL statement such as
EXEC SQL SELECT empno INTO :emp_num FROM emp WHERE ename=N'<Japanese_string>';
contains a multi-byte character string (<Japanese_string> could actually be Kanji), since the N character literal preceding the string identifies it as a multi-byte string. Since Oracle8 is case-insensitive, you can use "n" or "N" in the example.
You cannot use datatype equivalencing (the TYPE or VAR commands) with NLS multi-byte character strings.
Dynamic SQL method 4 is not available for NLS multi-byte character string host variables in Pro*C/C++.
You can use indicator variables with host character variables that are NLS multi-byte (as specified using the NLS_CHAR option).
LOB types can appear as table columns and also as object type attributes. These are the LOB datatypes: binary LOB (BLOB), character LOB (CLOB), National Character LOB (NCLOB) and binary external file LOB (BFILE).
A Pro*C/C++ host variable that corresponds to a LOB attribute in a table must be declared as OCIBlobLocator*, OCIClobLocator*, or OCIBfileLocator* depending on its LOB type. These special LOB locator types are defined in the OCI header file oci.h. In case a LOB column appears as an object type attribute, OTT (Object Type Translator) will translate the attribute to a LOB descriptor pointer of the appropriate type.
An indicator variable for the LOB descriptors is a signed 2-byte scalar quantity, declared as OCIInd.
Host variables for LOB locators are structures that are dynamically allocated and freed. The memory management scheme differs somewhat based on whether the LOB locator is for a relational column or for an embedded object type attribute, the important difference being that memory for an embedded LOB locator comes from the object cache during allocation of the object itself, whereas other LOB locators do not reside in the object cache.
When it is used as a host variable for a column, you must explicitly allocate memory for a LOB locator using the EXEC SQL ALLOCATE command before using it in any embedded SQL or PL/SQL statement. At the end of its use, you free a previously-allocated locator with the EXEC SQL FREE command. The allocated space is also freed automatically by SQLLIB when all the database connections in Pro*C/C++ are closed.
At runtime, the ALLOCATE statement will allocate a LOB descriptor of the appropriate type based on the type of the host variable. Upon a successful allocation, the value of the LOB host variable will be set to point to the allocated memory.
Once a LOB locator has been allocated, the host variable may be used in SQL statements and in embedded PL/SQL blocks. See PL/SQL User's Guide and Reference
LOB data can be manipulated through the LOB locator host variables using OCI functions such as OCILobRead(), OCILobWrite(), OCILobOpenFile() etc., to read, write, and otherwise manipulate LOB data.
An alternative way to operate on LOB data is to use PL/SQL stored procedures defined in the package `dbms_lob'. This will be illustrated by a sample program.
The following program illustrates the use of LOB variables. The EXEC SQL TYPE command is used to equivalence a blob variable with a LONG RAW datatype 8192 bytes in length.
A stream of binary data, (from a blob variable) is stored in a database BLOB column using a PL/SQL procedure, Store_Obj, which has procedure DBMS_LOB.WRITE embedded in it. Then the data is retrieved using a PL/SQL procedure, Get_Obj, which has procedure DBMS_LOB.READ embedded in it. The buffers holding the output data and the input data are then compared for equality.
#include <stdio.h> #include <string.h> #include <sqlca.h> #define LENGTH 8192 typedef char blob[LENGTH]; EXEC SQL TYPE blob IS LONG RAW(LENGTH); void sqlerror() { EXEC SQL WHENEVER SQLERROR CONTINUE; printf("%.*s\n", sqlca.sqlerrm.sqlerrml, sqlca.sqlerrm.sqlerrmc); EXEC SQL ROLLBACK WORK RELEASE; exit(1); } void main() { EXEC SQL BEGIN DECLARE SECTION; char *usr = "scott/tiger"; int size1; int size2; blob b1; blob b2; EXEC SQL END DECLARE SECTION; EXEC SQL WHENEVER SQLERROR DO sqlerror(); EXEC SQL CONNECT :usr; printf("Initialize BLOB buffers\n"); memset(b1, 65, LENGTH); b1[LENGTH-1]=0; memset(b2, 95, LENGTH); b2[LENGTH-1]=0; size1 = LENGTH; size2 = LENGTH; printf("Writing BLOB from buffer #1\n"); EXEC SQL EXECUTE BEGIN Store_Obj(:b1, :size1); END; END-EXEC; EXEC SQL COMMIT; printf("Reading BLOB into buffer #2\n"); EXEC SQL EXECUTE BEGIN Get_Obj(:b2, :size2); END; END-EXEC; printf("Write and Read Succeeded\n"); if (!strcmp((const char *)b1, (const char *)b2)) printf("BLOB buffers are Equal\n"); else { int i; for (i = 0; i < LENGTH; i++) if (b1[i] != b2[i]) break; printf("BLOB buffers differ at index %d\n", i); } EXEC SQL ROLLBACK WORK RELEASE; exit(0); }
For more information on LOBs, see Oracle8 Server Application Developer's Guide. For more information on embedding PL/SQL, see "Using Embedded PL/SQL" in this guide. For more information on the EXEC SQL TYPE command, see "User-Defined Type Equivalencing"on page 3 - 60.
You can use cursor variables in your Pro*C/C++ program for queries. A cursor variable is a handle for a cursor that must be defined and opened on the Oracle (release 7.2 or later) server, using PL/SQL. See the PL/SQL User's Guide and Reference for complete information about cursor variables.
The advantages of cursor variables are:
You declare a cursor variable in your Pro*C/C++ program using the Pro*C/C++ pseudotype SQL_CURSOR. For example:
EXEC SQL BEGIN DECLARE SECTION; sql_cursor emp_cursor; /* a cursor variable */ SQL_CURSOR dept_cursor; /* another cursor variable */ sql_cursor *ecp; /* a pointer to a cursor variable */ ... EXEC SQL END DECLARE SECTION; ecp = &emp_cursor; /* assign a value to the pointer */
You can declare a cursor variable using the type specification SQL_CURSOR, in all upper case, or sql_cursor, in all lower case; you cannot use mixed case.
A cursor variable is just like any other host variable in the Pro*C/C++ program. It has scope, following the scope rules of C. You can pass it as a parameter to other functions, even functions external to the source file in which you declared it. You can also define functions that return cursor variables, or pointers to cursor variables.
Caution: A SQL_CURSOR is implemented as a C struct in the code that Pro*C/C++ generates. So you can always pass it by pointer to another function, or return a pointer to a cursor variable from a function. But you can only pass it or return it by value if your C compiler supports these operations.
Before you can use a cursor variable, either to open it or to FETCH it, you must allocate the cursor. You do this using the new precompiler command ALLOCATE. For example, to allocate the SQL_CURSOR emp_cursor that was declared in the example above, you write the statement:
EXEC SQL ALLOCATE :emp_cursor;
Allocating a cursor does not require a call to the server, either at precompile time or at runtime. If the ALLOCATE statement contains an error (for example, an undeclared host variable), Pro*C/C++ issues a precompile time (PCC) error. Allocating a cursor variable does cause heap memory to be used. For this reason, you should normally avoid allocating a cursor variable in a program loop. Memory allocated for cursor variables is not freed when the cursor is closed, but only when the connection is closed.
You must open a cursor variable on the Oracle8 Server. You cannot use the embedded SQL OPEN command to open a cursor variable. You can open a cursor variable either by calling a PL/SQL stored procedure that opens the cursor (and defines it in the same statement). Or, you can open and define a cursor variable using an anonymous PL/SQL block in your Pro*C/C++ program.
For example, consider the following PL/SQL package, stored in
the database:
CREATE PACKAGE demo_cur_pkg AS TYPE EmpName IS RECORD (name VARCHAR2(10)); TYPE cur_type IS REF CURSOR RETURN EmpName; PROCEDURE open_emp_cur ( curs IN OUT cur_type, dept_num IN NUMBER); END; CREATE PACKAGE BODY demo_cur_pkg AS CREATE PROCEDURE open_emp_cur ( curs IN OUT cur_type, dept_num IN NUMBER) IS BEGIN OPEN curs FOR SELECT ename FROM emp WHERE deptno = dept_num ORDER BY ename ASC; END; END;
After this package has been stored, you can open the cursor curs by calling the open_emp_cur stored procedure from your Pro*C/C++ program, and FETCH from the cursor in the program. For example:
... sql_cursor emp_cursor; char emp_name[11]; ... EXEC SQL ALLOCATE :emp_cursor; /* allocate the cursor variable */ ... /* Open the cursor on the server side. */ EXEC SQL EXECUTE begin demo_cur_pkg.open_emp_cur(:emp_cursor, :dept_num); end; ; EXEC SQL WHENEVER NOT FOUND DO break; for (;;) { EXEC SQL FETCH :emp_cursor INTO :emp_name; printf("%s\n", emp_name); } ...
To open a cursor using a PL/SQL anonymous block in your Pro*C/C++ program, you define the cursor in the anonymous block. For example:
int dept_num = 10; ... EXEC SQL EXECUTE BEGIN OPEN :emp_cursor FOR SELECT ename FROM emp WHERE deptno = :dept_num; END; END-EXEC; ...
The above examples show how to use PL/SQL to open a cursor variable. You can also open a cursor variable using embedded SQL with the CURSOR clause:
... sql_cursor emp_cursor; ... EXEC ORACLE OPTION(select_error=no); EXEC SQL SELECT CURSOR(SELECT ename FROM emp WHERE deptno = :dept_num) INTO :emp_cursor FROM DUAL; EXEC ORACLE OPTION(select_error=yes);
In the above statement, the emp_cursor cursor variable is bound to the first column of the outermost select. The first column is itself a query, but it is represented in the form compatible with a sql_cursor host variable since the CURSOR(...) conversion clause is used.
Before using queries which involve the CURSOR clause, you must set the select_error option to NO. This will prevent the cancellation of the parent cursor and allow the program to run without errors.
In the example above, a reference cursor was defined inside a package, and the cursor was opened in a procedure in that package. But it is not always necessary to define a reference cursor inside the package that contains the procedures that open the cursor.
If you need to open a cursor inside a stand-alone stored procedure, you can define the cursor in a separate package, and then reference that package in the stand-alone stored procedure that opens the cursor. Here is an example:
PACKAGE dummy IS TYPE EmpName IS RECORD (name VARCHAR2(10)); TYPE emp_cursor_type IS REF CURSOR RETURN EmpName; END; -- and then define a stand-alone procedure: PROCEDURE open_emp_curs ( emp_cursor IN OUT dummy.emp_cursor_type; dept_num IN NUMBER) IS BEGIN OPEN emp_cursor FOR SELECT ename FROM emp WHERE deptno = dept_num; END; END;
When you define a reference cursor in a PL/SQL stored procedure, you must declare the type that the cursor returns. See the PL/SQL User's Guide and Reference for complete information on the reference cursor type and its return types.
Use the CLOSE command to close a cursor variable. For example, to close the emp_cursor cursor variable that was OPENed in the examples above, use the embedded SQL statement:
EXEC SQL CLOSE :emp_cursor;
Note that the cursor variable is a host variable, and so you must precede it with a colon.
You can re-use ALLOCATEd cursor variables. You can open, FETCH, and CLOSE as many times as needed for your application. However, if you disconnect from the server, then reconnect, you must re-ALLOCATE cursor variables.
Note: Cursors are automatically de-allocated by the SQLLIB runtime library upon exiting the current connection.
You can share a Pro*C/C++ cursor variable with an OCI function. To do so, you must use the SQLLIB conversion functions, sqlcdat() and sqlcur(). These functions convert between OCI cursor data areas and Pro*C/C++ cursor variables.
The sqlcdat() function translates an allocated cursor variable to an OCI cursor data area. The syntax is:
void sqlcdat(Cda_Def *cda, void *cur, int *retval);
where the parameters are:
|
cda |
A pointer to the destination OCI cursor data area. |
|
cur |
A pointer to the source Pro*C/C++ cursor variable. |
|
retval |
0 if no error, otherwise a SQLLIB (SQL) error number. |
Note: In the case of an error, the V2 and rc return code fields in the CDA also receive the error codes. The rows processed count field in the CDA is not set.
The sqlcur() function translates an OCI cursor data area to a Pro*C/C++ cursor variable. The syntax is:
void sqlcur(void *cur, Cda_Def *cda, int *retval);
where the parameters are:
|
cur |
A pointer to the destination Pro*C/C++ cursor variable. |
|
cda |
A pointer to the source OCI cursor data area. |
|
retval |
0 if no error, otherwise an error code. |
Note: The SQLCA structure is not updated by this routine. The SQLCA components are only set after a database operation is performed using the translated cursor.
ANSI and K&R prototypes for these functions are provided in the sql2oci.h header file. Memory for both cda and cur must be allocated prior to calling these functions.
The following restrictions apply to the use of cursor variables:
The following sample programs-a PL/SQL script and a Pro*C/C++ program-demonstrate how you can use cursor variables. These sources are available on-line in your demo directory.
-- PL/SQL source for a package that declares and -- opens a ref cursor CONNECT SCOTT/TIGER CREATE OR REPLACE PACKAGE emp_demo_pkg as TYPE emp_cur_type IS REF CURSOR RETURN emp%ROWTYPE; PROCEDURE open_cur(curs IN OUT emp_cur_type, dno IN NUMBER); END emp_demo_pkg; CREATE OR REPLACE PACKAGE BODY emp_demo_pkg AS PROCEDURE open_cur(curs IN OUT emp_cur_type, dno IN NUMBER) IS BEGIN OPEN curs FOR SELECT * FROM emp WHERE deptno = dno ORDER BY ename ASC; END; END emp_demo_pkg;
/* * Fetch from the EMP table, using a cursor variable. * The cursor is opened in the stored PL/SQL procedure * open_cur, in the EMP_DEMO_PKG package. * * This package is available on-line in the file * sample11.sql, in the demo directory. * */ #include <stdio.h> #include <sqlca.h> /* Error handling function. */ void sql_error(); main() { char temp[32]; EXEC SQL BEGIN DECLARE SECTION; char *uid = "scott/tiger"; SQL_CURSOR emp_cursor; int dept_num; struct { int emp_num; char emp_name[11]; char job[10]; int manager; char hire_date[10]; float salary; float commission; int dept_num; } emp_info; struct { short emp_num_ind; short emp_name_ind; short job_ind; short manager_ind; short hire_date_ind; short salary_ind; short commission_ind; short dept_num_ind; } emp_info_ind; EXEC SQL END DECLARE SECTION; EXEC SQL WHENEVER SQLERROR do sql_error("Oracle error"); /* Connect to Oracle. */ EXEC SQL CONNECT :uid; /* Allocate the cursor variable. */ EXEC SQL ALLOCATE :emp_cursor; /* Exit the inner for (;;) loop when NO DATA FOUND. */ EXEC SQL WHENEVER NOT FOUND DO break; for (;;) { printf("\nEnter department number (0 to exit): "); gets(temp); dept_num = atoi(temp); if (dept_num <= 0) break; EXEC SQL EXECUTE begin emp_demo_pkg.open_cur(:emp_cursor, :dept_num); end; END-EXEC; printf("\nFor department %d--\n", dept_num); printf("ENAME\t SAL\t COMM\n"); printf("-----\t ---\t ----\n"); /* Fetch each row in the EMP table into the data struct. Note the use of a parallel indicator struct. */ for (;;) { EXEC SQL FETCH :emp_cursor INTO :emp_info INDICATOR :emp_info_ind; printf("%s\t", emp_info.emp_name); printf("%8.2f\t\t", emp_info.salary); if (emp_info_ind.commission_ind != 0) printf(" NULL\n"); else printf("%8.2f\n", emp_info.commission); } } /* Close the cursor. */ EXEC SQL CLOSE :emp_cursor; exit(0); } void sql_error(msg) char *msg; { long clen, fc; char cbuf[128]; clen = (long) sizeof (cbuf); sqlgls(cbuf, &clen, &fc); printf("\n%s\n", msg); printf("Statement is--\n%s\n", cbuf); printf("Function code is %ld\n\n", fc); sqlglm(cbuf, (int *) &clen, (int *) &clen); printf ("\n%.*s\n", clen, cbuf); EXEC SQL WHENEVER SQLERROR CONTINUE; EXEC SQL ROLLBACK WORK; exit(-1); }
Your Pro*C/C++ program must connect to Oracle8 before querying or manipulating data. To log on, simply use the CONNECT statement
EXEC SQL CONNECT :username IDENTIFIED BY :password;
where username and password are char or VARCHAR host variables.
Or, you can use the statement
EXEC SQL CONNECT :usr_pwd;
where the host variable usr_pwd contains your username and password separated by a slash character (/).
The CONNECT statement must be the first SQL statement executed by the program. That is, other SQL statements can physically but not logically precede the CONNECT statement in the precompilation unit.
To supply the Oracle8 username and password separately, you define two host variables as character strings or VARCHARs. (If you supply a username containing both username and password, only one host variable is needed.)
Make sure to set the username and password variables before the CONNECT is executed, or it will fail. Your program can prompt for the values, or you can hard code them as follows:
char *username = "SCOTT"; char *password = "TIGER"; ... EXEC SQL WHENEVER SQLERROR ... EXEC SQL CONNECT :username IDENTIFIED BY :password;
However, you cannot hard code a username and password into the CONNECT statement. Nor can you use quoted literals. For example, both of the following statements are invalid:
EXEC SQL CONNECT SCOTT IDENTIFIED BY TIGER; EXEC SQL CONNECT 'SCOTT' IDENTIFIED BY 'TIGER';
To connect using a Net8 driver, substitute a service name, as defined in your tnsnames.ora configuration file or in Oracle Names.
If you are using Oracle Names, the name server obtains the service name from the network definition database.
Note: SQL*Net V1 does not work with Oracle8.
See Oracle Net8 Administrator's Guide for more information about Net8.
You can automatically connect to Oracle8 with the username
OPS$username
where username is the current operating system username, and OPS$username is a valid Oracle8 database username. (The actual value for OPS$ is defined in the INIT.ORA parameter file.) You simply pass to the Pro*C/C++ Precompiler a slash character, as follows:
... char *oracleid = "/"; ... EXEC SQL CONNECT :oracleid;
This automatically connects you as user OPS$username. For example, if your operating system username is RHILL, and OPS$RHILL is a valid Oracle8 username, connecting with '/' automatically logs you on to Oracle8 as user OPS$RHILL.
You can also pass a '/' in a string to the precompiler. However, the string cannot contain trailing blanks. For example, the following CONNECT statement will fail:
... char oracleid[10] = "/ "; ... EXEC SQL CONNECT :oracleid;
If AUTO_CONNECT=YES, and the application is not already connected to a database when it processes the first executable SQL statement, it attempts to connect using the userid
OPS$<username>
where username is your current operating system user or task name and OPS$username is a valid Oracle8 userid. The default value of AUTO_CONNECT is NO.
When AUTO_CONNECT=NO, you must use the CONNECT statement in your program to connect to Oracle.
The Pro*C/C++ Precompiler supports distributed processing via Net8 Your application can concurrently access any combination of local and remote databases or make multiple connections to the same database. In Figure 4-1, an application program communicates with one local and three remote Oracle8 databases. ORA2, ORA3, and ORA4 are simply logical names used in CONNECT statements.

By eliminating the boundaries in a network between different machines and operating systems, Net8 provides a distributed processing environment for Oracle8 tools. This section shows you how Pro*C/C++ supports distributed processing via Net8. You learn how your application can
For details on installing Net8 and identifying available databases, refer to the Oracle Net8 Administrator's Guide and your system-specific Oracle8 documentation.
The communicating points in a network are called nodes. Net8 lets you transmit information (SQL statements, data, and status codes) over the network from one node to another.
A protocol is a set of rules for accessing a network. The rules establish such things as procedures for recovering after a failure and formats for transmitting data and checking errors.
The Net8 syntax for connecting to the default database in the local domain is simply to use the service name for the database.
If the service name is not in the default (local) domain, you must use a global specification (all domains specified). For example:
HR.US.ORACLE.COM
Each node has a default database. If you specify a database name, but no domain, in your CONNECT statement, you connect to the default database on the named local or remote node.
A default connection is made by a CONNECT statement that has no AT clause. The connection can be to any default or non-default database at any local or remote node. SQL statements without an AT clause are executed against the default connection. Conversely, a non-default connection is made by a CONNECT statement that has an AT clause. SQL statements with an AT clause are executed against the non-default connection.
All database names must be unique, but two or more database names can specify the same connection. That is, you can have multiple connections to any database on any node.
Usually, you establish a connection to Oracle8 as follows:
EXEC SQL CONNECT :username IDENTIFIED BY :password;
You can also use
EXEC SQL CONNECT :usr_pwd;
where usr_pwd contains username/password.
You can automatically connect to Oracle8 with the userid
OPS$username
where username is your current operating system user or task name and OPS$username is a valid Oracle8 userid. You simply pass to the precompiler a slash (/) character, as follows:
char oracleid = '/'; ... EXEC SQL CONNECT :oracleid;
This automatically connects you as user OPS$username.
If you do not specify a database and node, you are connected to the default database at the current node. If you want to connect to a different database, you must explicitly identify that database.
With explicit connections, you connect to another database directly, giving the connection a name that will be referenced in SQL statements. You can connect to several databases at the same time and to the same database multiple times.
In the following example, you connect to a single non-default database at a remote node:
/* declare needed host variables */ char username[10] = "scott"; char password[10] = "tiger"; char db_string[20] = "NYNON"; /* give the database connection a unique name */ EXEC SQL DECLARE DB_NAME DATABASE; /* connect to the non-default database */ EXEC SQL CONNECT :username IDENTIFIED BY :password AT DB_NAME USING :db_string;
The identifiers in this example serve the following purposes:
The USING clause specifies the network, machine, and database to be associated with DB_NAME. Later, SQL statements using the AT clause (with DB_NAME) are executed at the database specified by db_string.
Alternatively, you can use a character host variable in the AT clause, as the following example shows:
/* declare needed host variables */ char username[10] = "scott"; char password[10] = "tiger"; char db_name[10] = "oracle1"; char db_string[20] = "NYNON"; /* connect to the non-default database using db_name */ EXEC SQL CONNECT :username IDENTIFIED BY :password AT :db_name USING :db_string; ...
If db_name is a host variable, the DECLARE DATABASE statement is not needed. Only if DB_NAME is an undeclared identifier must you execute a DECLARE DB_NAME DATABASE statement before executing a CONNECT ... AT DB_NAME statement.
If granted the privilege, you can execute any SQL data manipulation statement at the non-default connection. For example, you might execute the following sequence of statements:
EXEC SQL AT DB_NAME SELECT ... EXEC SQL AT DB_NAME INSERT ... EXEC SQL AT DB_NAME UPDATE ...
In the next example, db_name is a host variable:
EXEC SQL AT :db_name DELETE ...
If db_name is a host variable, all database tables referenced by the SQL statement must be defined in DECLARE TABLE statements. Otherwise, the precompiler issues a warning.
For more information, see "Using DECLARE TABLE" on page D-5, and "DECLARE TABLE (Oracle Embedded SQL Directive)" on page F-27.
You can execute a PL/SQL block using the AT clause. The following example shows the syntax:
EXEC SQL AT :db_name EXECUTE begin /* PL/SQL block here */ end; END-EXEC;
Cursor control statements such as OPEN, FETCH, and CLOSE are exceptions-they never use an AT clause. If you want to associate a cursor with an explicitly identified database, use the AT clause in the DECLARE CURSOR statement, as follows:
EXEC SQL AT :db_name DECLARE emp_cursor CURSOR FOR ... EXEC SQL OPEN emp_cursor ... EXEC SQL FETCH emp_cursor ... EXEC SQL CLOSE emp_cursor;
If db_name is a host variable, its declaration must be within the scope of all SQL statements that refer to the DECLAREd cursor. For example, if you OPEN the cursor in one subprogram, then FETCH from it in another subprogram, you must declare db_name globally.
When OPENing, CLOSing, or FETCHing from the cursor, you do not use the AT clause. The SQL statements are executed at the database named in the AT clause of the DECLARE CURSOR statement or at the default database if no AT clause is used in the cursor declaration.
The AT :host_variable clause allows you to change the connection associated with a cursor. However, you cannot change the association while the cursor is open. Consider the following example:
EXEC SQL AT :db_name DECLARE emp_cursor CURSOR FOR ... strcpy(db_name, "oracle1"); EXEC SQL OPEN emp_cursor; EXEC SQL FETCH emp_cursor INTO ... strcpy(db_name, "oracle2"); EXEC SQL OPEN emp_cursor; /* illegal, cursor still open */ EXEC SQL FETCH emp_cursor INTO ...
This is illegal because emp_cursor is still open when you try to execute the second OPEN statement. Separate cursors are not maintained for different connections; there is only one emp_cursor, which must be closed before it can be reopened for another connection. To debug the last example, simply close the cursor before reopening it, as follows:
... EXEC SQL CLOSE emp_cursor; -- close cursor first strcpy(db_name, "oracle2"); EXEC SQL OPEN emp_cursor; EXEC SQL FETCH emp_cursor INTO ...
Dynamic SQL statements are similar to cursor control statements in that some never use the AT clause.
For dynamic SQL Method 1, you must use the AT clause if you want to execute the statement at a non-default connection. An example follows:
EXEC SQL AT :db_name EXECUTE IMMEDIATE :sql_stmt;
For Methods 2, 3, and 4, you use the AT clause only in the DECLARE STATEMENT statement if you want to execute the statement at a non-default connection. All other dynamic SQL statements such as PREPARE, DESCRIBE, OPEN, FETCH, and CLOSE never use the AT clause. The next example shows Method 2:
EXEC SQL AT :db_name DECLARE sql_stmt STATEMENT; EXEC SQL PREPARE slq_stmt FROM :sql_string; EXEC SQL EXECUTE sql_stmt;
The following example shows Method 3:
EXEC SQL AT :db_name DECLARE sql_stmt STATEMENT; EXEC SQL PREPARE slq_stmt FROM :sql_string; EXEC SQL DECLARE emp_cursor CURSOR FOR sql_stmt; EXEC SQL OPEN emp_cursor ... EXEC SQL FETCH emp_cursor INTO ... EXEC SQL CLOSE emp_cursor;
You can use the AT db_name clause for multiple explicit connections, just as you can for a single explicit connection. In the following example, you connect to two non-default databases concurrently:
/* declare needed host variables */ char username[10] = "scott"; char password[10] = "tiger"; char db_string1[20] = "NYNON1"; char db_string2[20] = "CHINON"; ... /* give each database connection a unique name */ EXEC SQL DECLARE DB_NAME1 DATABASE; EXEC SQL DECLARE DB_NAME2 DATABASE; /* connect to the two non-default databases */ EXEC SQL CONNECT :username IDENTIFIED BY :password AT DB_NAME1 USING :db_string1; EXEC SQL CONNECT :username IDENTIFIED BY :password AT DB_NAME2 USING :db_string2;
The identifiers DB_NAME1 and DB_NAME2 are declared and then used to name the default databases at the two non-default nodes so that later SQL statements can refer to the databases by name.
Alternatively, you can use a host variable in the AT clause, as the following example shows:
/* declare needed host variables */ char username[10] = "scott"; char password[10] = "tiger"; char db_name[20]; char db_string[20]; int n_defs = 3; /* number of connections to make */ ... for (i = 0; i < n_defs; i++) { /* get next database name and Net8 string */ printf("Database name: "); gets(db_name); printf("Net8) string: "); gets(db_string); /* do the connect */ EXEC SQL CONNECT :username IDENTIFIED BY :password AT :db_name USING :db_string; }
You can also use this method to make multiple connections to the same database, as the following example shows:
strcpy(db_string, "NYNON"); for (i = 0; i < ndefs; i++) { /* connect to the non-default database */ printf("Database name: "); gets(db_name); EXEC SQL CONNECT :username IDENTIFIED BY :password AT :db_name USING :db_string; } ...
You must use different database names for the connections, even though they use the same Net8 string. However, you can connect twice to the same database using just one database name because that name identifies the default and non-default databases.
Your application program must ensure the integrity of transactions that manipulate data at two or more remote databases. That is, the program must commit or roll back all SQL statements in the transactions. This might be impossible if the network fails or one of the systems crashes.
For example, suppose you are working with two accounting databases. You debit an account on one database and credit an account on the other database, then issue a COMMIT at each database. It is up to your program to ensure that both transactions are committed or rolled back.
Implicit connections are supported through the Oracle8 distributed query facility, which does not require explicit connections, but only supports the SELECT statement. A distributed query allows a single SELECT statement to access data on one or more non-default databases.
The distributed query facility depends on database links, which assign a name to a CONNECT statement rather than to the connection itself. At run time, the embedded SELECT statement is executed by the specified Oracle8 Server, which implicitly connects to the non-default database(s) to get the required data.
In the next example, you connect to a single non-default database. First, your program executes the following statement to define a database link (database links are usually established interactively by the DBA or user):
EXEC SQL CREATE DATABASE LINK db_link CONNECT TO username IDENTIFIED BY password USING 'NYNON';
Then, the program can query the non-default EMP table using the database link, as follows:
EXEC SQL SELECT ENAME, JOB INTO :emp_name, :job_title FROM emp@db_link WHERE DEPTNO = :dept_number;
The database link is not related to the database name used in the AT clause of an embedded SQL statement. It simply tells Oracle8 where the non-default database is located, the path to it, and what Oracle8 username and password to use. The database link is stored in the data dictionary until it is explicitly dropped.
In our example, the default Oracle8 Server logs on to the non-default database via Net8 using the database link db_link. The query is submitted to the default Server, but is "forwarded" to the non-default database for execution.
To make referencing the database link easier, you can create a synonym as follows (again, this is usually done interactively):
EXEC SQL CREATE SYNONYM emp FOR emp@db_link;
Then, your program can query the non-default EMP table, as follows:
EXEC SQL SELECT ENAME, JOB INTO :emp_name, :job_title FROM emp WHERE DEPTNO = :dept_number;
This provides location transparency for emp.
In the following example, you connect to two non-default databases concurrently. First, you execute the following sequence of statements to define two database links and create two synonyms:
EXEC SQL CREATE DATABASE LINK db_link1 CONNECT TO username1 IDENTIFIED BY password1 USING 'NYNON'; EXEC SQL CREATE DATABASE LINK db_link2 CONNECT TO username2 IDENTIFIED BY password2 USING 'CHINON'; EXEC SQL CREATE SYNONYM emp FOR emp@db_link1; EXEC SQL CREATE SYNONYM dept FOR dept@db_link2;
Then, your program can query the non-default EMP and DEPT tables, as follows:
EXEC SQL SELECT ENAME, JOB, SAL, LOC FROM emp, dept WHERE emp.DEPTNO = dept.DEPTNO AND DEPTNO = :dept_number;
Oracle8 executes the query by performing a join between the non-default EMP table at db_link1 and the non-default DEPT table at db_link2.
Pro*C/C++ now provides client applications with a convenient way to change a user password at runtime through a simple extension to the EXEC SQL CONNECT statement.
The syntax for the CONNECT statement now has an optional ALTER AUTHORIZATION clause. The new syntax for CONNECT is shown here:
EXEC SQL CONNECT { :user IDENTIFIED BY :oldpswd | :usr_psw } [ [ AT { dbname | :host_variable }] USING :connect_string ] [ ALTER AUTHORIZATION :newpswd ]
This section describes the possible outcomes of different variations of the ALTER AUTHORIZATION clause..
If an application issues the following statement
EXEC SQL CONNECT ..; /* No ALTER AUTHORIZATION clause */
it performs a normal connection attempt. The possible results include the following:
The following CONNECT statement
EXEC SQL CONNECT .. ALTER AUTHORIZATION :newpswd;
indicates that the application wants to change the account password to the value indicated by newpswd. After the change is made, an attempt is made to connect as user/newpswd. This can have the following results:
This simple example is intended to demonstrate all the variations on the syntax of the new clause used with the connect statement. When run, this program switches the password between 'tiger' and 'lion' repeatedly, returning it to 'tiger' before completing. (inst1_alias is a loopback to the same database.)
#include <sqlca.h> main() { char *userpass = "scott/tiger"; char *user = "scott"; char *pass = "tiger"; char *atdb = "remote"; char *using = "inst1_alias"; char *newpw = "lion"; char *newuserpass = "scott/lion"; exec sql whenever sqlerror do printf("%.70s\n",sqlca.sqlerrm.sqlerrmc); exec sql connect :userpass alter authorization :newpw; exec sql connect :user identified by :newpw alter authorization :pass; exec sql connect :userpass at :atdb using :using alter authorization :newpw; exec sql connect :user identified by :newpw at :atdb using :using alter authorization :pass; exec sql connect :userpass using :using alter authorization :newpw; exec sql connect :newuserpass; exec sql connect :user identified by :newpw; exec sql connect :newuserpass at :atdb using :using; exec sql connect :newuserpass using :using; exec sql connect :user identified by :newpw at :atdb using :using; exec sql connect :newuserpass alter authorization :pass; exit(0); }
To embed OCI calls in your Pro*C/C++ program, take the following steps:
That way, the Pro*C/C++ Precompiler and the OCI "know" that they are working together. However, there is no sharing of Oracle8 cursors.
You need not worry about declaring the OCI Host Data Area (HDA) because the Oracle8 runtime library manages connections and maintains the HDA for you.
You set up the LDA by issuing the OCI call
sqllda(&lda);
where lda identifies the LDA data structure.
If the setup fails, the lda_rc field in the lda is set to 1012 to indicate the error.
A call to sqllda() sets up an LDA for the connection used by the most recently executed SQL statement. To set up the different LDAs needed for additional connections, just call sqllda() with a different lda after each CONNECT. In the following example, you connect to two non-default databases concurrently:
#include <ocidfn.h> Lda_Def lda1; Lda_Def lda2; char username[10], password[10], db_string1[20], dbstring2[20]; ... strcpy(username, "scott"); strcpy(password, "tiger"); strcpy(db_string1, "NYNON"); strcpy(db_string2, "CHINON"); /* give each database connection a unique name */ EXEC SQL DECLARE DB_NAME1 DATABASE; EXEC SQL DECLARE DB_NAME2 DATABASE; /* connect to first non-default database */ EXEC SQL CONNECT :username IDENTIFIED BY :password; AT DB_NAME1 USING :db_string1; /* set up first LDA */ sqllda(&lda1); /* connect to second non-default database */ EXEC SQL CONNECT :username IDENTIFIED BY :password; AT DB_NAME2 USING :db_string2; /* set up second LDA */ sqllda(&lda2);
DB_NAME1 and DB_NAME2 are not C variables; they are SQL identifiers. You use them only to name the default databases at the two non-default nodes, so that later SQL statements can refer to the databases by name.
The new names of SQLLIB functions are listed in Table 4-2. You can use these SQLLIB functions for both threaded and non-threaded applications. Previously, for example, sqlglm() was documented as the non-threaded version of this function, while sqlglmt() was the threaded version. The names sqlglm() and sqlglmt() are still available, but are deprecated in release 8.0. The new function, SQLErrorGetText(), requires the same arguments as sqlglmt() . For non-threaded applications, pass the defined constant SQL_SINGLE_RCTX as the context.
Each standard SQLLIB public function is thread-safe and accepts the runtime context as the first argument. For example, the syntax for SQLErrorGetText() is:
void SQLErrorGetText(dvoid *context, char *message_buffer, size_t *buffer_size, size_t *message_length);
In summary, the old function names will continue to work in your existing applications. You can use the new function names in the new applications that you will write.
Table 4-2 is a list of all the SQLLIB public functions and their corresponding syntax. Cross-references to the non-threaded usages are provided to help you find more complete descriptions.
Attention: For the specific datatypes used in the argument lists for these functions, refer to your platform-specific sqlcpr.h file.
| Old Name | New Function Prototype | Cross-reference |
|---|---|---|
sqlaldt() |
struct SQLDA *SQLSQLDAAlloc(dvoid *context, unsigned int maximum_variables, unsigned int maximum_name_length, unsigned int maximum_ind_name_length); |
see also sqlaldt() on page 14-5 |
sqlcdat() |
void SQLCDAFromResultSetCursor(dvoid *context, Cda_Def *cda, void *cursor, sword *return_value); |
see also sqlcdat() on page 4-16 |
sqlclut() |
void SQLSQLDAFree(dvoid *context, struct SQLDA *descriptor_name); |
see also sqlcu() on page 14-37 |
sqlcurt() |
void SQLCDAToResultSetCursor(dvoid *context, void *cursor, Cda_Def *cda, sword *return_value) |
see also sqlclur() on page 4-16 |
sqlglmt() |
void SQLErrorGetText(dvoid *context, char *message_buffer, size_t *buffer_size, size_t *message_length); |
see also sqlglm() on "Getting the Full Text of Error Messages" on page 11-23 |
sqlglst() |
void SQLStmtGetText(dvoid *context, char *statement_buffer, size_t *statement_length, size_t *sqlfc); |
see also sqlgls() on "Obtaining the Text of SQL Statements" on page 11-32 |
sqlld2t() |
void SQLLDAGetNamed(dvoid *context, Lda_Def *lda, text *cname, sb4 *cname_length); |
see also sqlld2() on page 4-62 |
sqlldat() |
void SQLCDAGetCurrent(dvoid *context, Lda_Def *lda); |
see also sqllda() on page 4-35 |
sqlnult() |
void SQLColumnNullCheck(dvoid *context, unsigned short *value_type, unsigned short *type_code, int *null_status); |
see also sqlnul() on page 14-17 |
sqlprct() |
void SQLNumberPrecV6(dvoid *context, long *length, int *precision, int *scale); |
see also sqlprc() on page 14-16 |
sqlpr2t() |
void SQLNumberPrecV7(dvoid *context, unsigned long *length, int *precision, int *scale); |
see also sqlpr2() on page 14-16 |
|
void SQLVarcharGetLength(dvoid *context, unsigned long *data_length, unsigned long *total_length); |
see also sqlvcp() on "Finding the Length of the VARCHAR Array Component" on page 3-46. |
Added in Pro*C/C++ rel 8. |
sword SQLEnvGet(dvoid *rctx, OCIEnv **oeh); |
|
Added in Pro*C/C++ rel 8. |
sword SQLSvcCtxGet(dvoid *rctx, text *dbmae, sb4 dbnamelen, OCISvcCtx **svc); |
If your development platform does not support threads, ignore this section.
Multi-threaded applications have multiple threads executing in a shared address space. Threads are "lightweight" subprocesses that execute within a process. They share code and data segments, but have their own program counters, machine registers and stack. Global and static variables are common to all threads, and a mutual exclusivity mechanism is often required to manage access to these variables from multiple threads within an application. Mutexes are the synchronization mechanism to insure that data integrity is preserved.
For further discussion of mutexes, see texts on multi-threading. For more detailed information about multi-threaded applications, refer to your thread-package specific reference material.
The Pro*C/C++ Precompiler supports development of multi-threaded Oracle8 Server applications (on platforms that support multi-threaded applications) using the following:
Attention: If your development platform does not support multi-threading, the information in this section does not apply.
Note: While your platform may support a particular thread package, see your platform-specific Oracle8 documentation to determine whether Oracle8 supports it.
The following topics discuss how to use the preceding features to develop multi-threaded Pro*C/C++ applications:
To loosely couple a thread and a connection, Pro*C/C++ introduces the notion of a runtime context. The runtime context includes the following resources and their current states:
Rather than simply supporting a loose coupling between threads and connections, the Pro*C/C++ Precompiler allows developers to loosely couple threads with runtime contexts. Pro*C/C++ allows an application to define a handle to a runtime context, and pass that handle from one thread to another.
For example, an interactive application spawns a thread, T1, to execute a query and return the first 10 rows to the application. T1 then terminates. After obtaining the necessary user input, another thread, T2, is spawned (or an existing thread is used) and the runtime context for T1 is passed to T2 so it can fetch the next 10 rows by processing the same cursor.
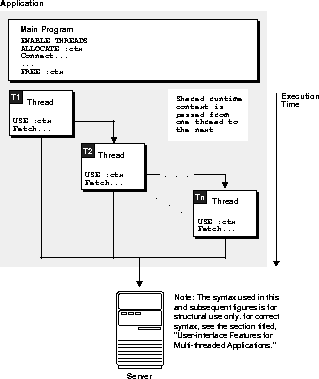
Two possible models for using runtime contexts in multi-threaded Pro*C/C++ applications are shown here:
Regardless of the model you use for runtime contexts, you cannot share a runtime context between multiple threads at the same time. If two or more threads attempt to use the same runtime context simultaneously, the following runtime error occurs:
SQL-02131: Runtime context in use
Figure 4-3 shows an application running in a multi-threaded environment. The various threads share a single runtime context to process one or more SQL statements. Again, runtime contexts cannot be shared by multiple threads at the same time. The mutexes in Figure 4-3 show how to prevent concurrent usage.
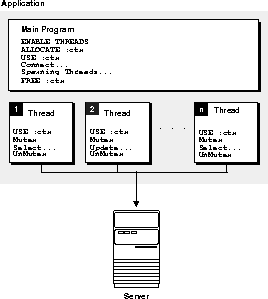
Figure 4-4 shows an application that executes multiple threads using multiple runtime contexts. In this situation, the application does not require mutexes, because each thread has a dedicated runtime context.

The Pro*C/C++ Precompiler provides the following user-interface features to support multi-threaded applications:
With THREADS=YES specified on the command line, the Pro*C/C++ Precompiler ensures that the generated code is thread-safe, given that you follow the guidelines described in "Programming Considerations" on page 4-47. With THREADS=YES specified, Pro*C/C++ verifies that all SQL statements execute within the scope of a user-defined runtime context. If your program does not meet this requirement, the following precompiler error is returned:
PCC-02390: No EXEC SQL CONTEXT USE statement encountered
The following embedded SQL statements and directives support the definition and usage of runtime contexts and threads:
For these EXEC SQL statements, context_var is the handle to the runtime context and must be declared of type sql_context as follows:
sql_context <context_variable>;
EXEC SQL ENABLE THREADS
This executable SQL statement initializes a process that supports multiple threads. This must be the first executable SQL statement in your multi-threaded application. For more detailed information, see "ENABLE THREADS (Executable Embedded SQL Extension)" on page F-36.
EXEC SQL CONTEXT ALLOCATE
This executable SQL statement allocates and initializes memory for the specified runtime context; the runtime-context variable must be declared of type sql_context. For more detailed information, see "CONTEXT ALLOCATE" on "CONTEXT ALLOCATE (Executable Embedded SQL Extension)" on page F-16.
This directive instructs the precompiler to use the specified runtime context for subsequent executable SQL statements. The runtime context specified must be previously allocated using an EXEC SQL CONTEXT ALLOCATE statement.
The EXEC SQL CONTEXT USE directive works similarly to the EXEC SQL WHENEVER directive in that it affects all executable SQL statements which positionally follow it in a given source file without regard to standard C scope rules. In the following example, the UPDATE statement in function2() uses the global runtime context, ctx1:
sql_context ctx1; /* declare global context ctx1 */ function1() { sql_context :ctx1; /* declare local context ctx1 */ EXEC SQL CONTEXT ALLOCATE :ctx1; EXEC SQL CONTEXT USE :ctx1; EXEC SQL INSERT INTO ... /* local ctx1 used for this stmt */ ... } function2() { EXEC SQL UPDATE ... /* global ctx1 used for this stmt */ }
In the next example, there is no global runtime context. The precompiler refers to the ctx1 runtime context in the generated code for the UPDATE statement. However, there is no context variable in scope for function2(), so errors are generated at compile time.
function1() { sql_context ctx1; /* local context variable declared */ EXEC SQL CONTEXT ALLOCATE :ctx1; EXEC SQL CONTEXT USE :ctx1; EXEC SQL INSERT INTO ... /* ctx1 used for this statement */ ... } function2() { EXEC SQL UPDATE ... /* Error! No context variable in scope */ }
For more detailed information, see "CONTEXT OBJECT OPTION GET (Executable Embedded SQL Extension)" on page F-18.
EXEC SQL CONTEXT FREE
This executable SQL statement frees the memory associated with the specified runtime context and places a null pointer in the host program variable. For more detailed information, see "CONTEXT FREE (Executable Embedded SQL Extension)" on page F-17.
Examples
The following code fragments show how to use embedded SQL statements and precompiler directives for two typical programming models; they use thread_create() to create threads.
The first example showing multiple threads using multiple runtime contexts:
main() { sql_context ctx1,ctx2; /* declare runtime contexts */ EXEC SQL ENABLE THREADS; EXEC SQL CONTEXT ALLOCATE :ctx1; EXEC SQL CONTEXT ALLOCATE :ctx2; ... /* spawn thread, execute function1 (in the thread) passing ctx1 */ thread_create(..., function1, ctx1); /* spawn thread, execute function2 (in the thread) passing ctx2 */ thread_create(..., function2, ctx2); ... EXEC SQL CONTEXT FREE :ctx1; EXEC SQL CONTEXT FREE :ctx2; ... } void function1(sql_context ctx) { EXEC SQL CONTEXT USE :ctx; /* execute executable SQL statements on runtime context ctx1!!! */ ... } void function2(sql_context ctx) { EXEC SQL CONTEXT USE :ctx; /* execute executable SQL statements on runtime context ctx2!!! */ ... }
The next example shows how to use multiple threads that share a common runtime context. Because the SQL statements executed in function1() and function2() potentially execute at the same time, you must place mutexes around every executable EXEC SQL statement to ensure serial, therefore safe, manipulation of the data.
main() { sql_context ctx; /* declare runtime context */ EXEC SQL CONTEXT ALLOCATE :ctx; ... /* spawn thread, execute function1 (in the thread) passing ctx */ thread_create(..., function1, ctx); /* spawn thread, execute function2 (in the thread) passing ctx */ thread_create(..., function2, ctx); ... } void function1(sql_context ctx) { EXEC SQL CONTEXT USE :ctx; /* Execute SQL statements on runtime context ctx. */ ... } void function2(sql_context ctx) { EXEC SQL CONTEXT USE :ctx; /* Execute SQL statements on runtime context ctx. */ ... }
While Oracle8 ensures that the SQLLIB code is thread-safe, you are responsible for ensuring that your Pro*C/C++ source code is designed to work properly with threads; for example, carefully consider your use of static and global variables.
In addition, multi-threaded requires design decisions regarding the following:
Also, no more than one executable embedded SQL statement, for example, EXEC SQL UPDATE, may be outstanding on a runtime context at a given time.
Existing requirements for precompiled applications also apply. For example, all references to a given cursor must appear in the same source file.
The following program is one approach to writing a multi-threaded embedded SQL application. The program creates as many sessions as there are threads. Each thread executes zero or more transactions, that are specified in a transient structure called "records."
Note: This program was developed specifically for a Sun workstation running Solaris. Either the DCE or Solaris threads package is usable with this program. See your platform-specific documentation for the availability of threads packages.
/* * Name: Thread_example1.pc * * Description: This program illustrates how to use threading in * conjunction with precompilers. The program creates as many * sessions as there are threads. Each thread executes zero or * more transactions, that are specified in a transient * structure called 'records'. * Requirements: * The program requires a table 'ACCOUNTS' to be in the schema * scott/tiger. The description of ACCOUNTS is: * SQL> desc accounts * Name Null? Type * ------------------------------- ------- ------ * ACCOUNT NUMBER(36) * BALANCE NUMBER(36,2) * * For proper execution, the table should be filled with the accounts * 10001 to 10008. * * */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sqlca.h> #define _EXC_OS_ _EXC__UNIX #define _CMA_OS_ _CMA__UNIX #ifdef DCE_THREADS #include <pthread.h> #else #include <thread.h> #endif /* Function prototypes */ void err_report(); #ifdef DCE_THREADS void do_transaction(); #else void *do_transaction(); #endif void get_transaction(); void logon(); void logoff(); #define CONNINFO "scott/tiger" #define THREADS 3 struct parameters { sql_context * ctx; int thread_id; }; typedef struct parameters parameters; struct record_log { char action; unsigned int from_account; unsigned int to_account; float amount; }; typedef struct record_log record_log; record_log records[]= { { 'M', 10001, 10002, 12.50 }, { 'M', 10001, 10003, 25.00 }, { 'M', 10001, 10003, 123.00 }, { 'M', 10001, 10003, 125.00 }, { 'M', 10002, 10006, 12.23 }, { 'M', 10007, 10008, 225.23 }, { 'M', 10002, 10008, 0.70 }, { 'M', 10001, 10003, 11.30 }, { 'M', 10003, 10002, 47.50 }, { 'M', 10002, 10006, 125.00 }, { 'M', 10007, 10008, 225.00 }, { 'M', 10002, 10008, 0.70 }, { 'M', 10001, 10003, 11.00 }, { 'M', 10003, 10002, 47.50 }, { 'M', 10002, 10006, 125.00 }, { 'M', 10007, 10008, 225.00 }, { 'M', 10002, 10008, 0.70 }, { 'M', 10001, 10003, 11.00 }, { 'M', 10003, 10002, 47.50 }, { 'M', 10008, 10001, 1034.54}}; static unsigned int trx_nr=0; #ifdef DCE_THREADS pthread_mutex_t mutex; #else mutex_t mutex; #endif /********************************************************************* * Main ********************************************************************/ main() { sql_context ctx[THREADS]; #ifdef DCE_THREADS pthread_t thread_id[THREADS]; pthread_addr_t status; #else thread_t thread_id[THREADS]; int status; #endif parameters params[THREADS]; int i; EXEC SQL ENABLE THREADS; EXEC SQL WHENEVER SQLERROR DO err_report(sqlca); /* Create THREADS sessions by connecting THREADS times */ for(i=0;i<THREADS;i++) { printf("Start Session %d....",i); EXEC SQL CONTEXT ALLOCATE :ctx[i]; logon(ctx[i],CONNINFO); } /*Create mutex for transaction retrieval */ #ifdef DCE_THREADS if (pthread_mutex_init(&mutex,pthread_mutexattr_default)) #else if (mutex_init(&mutex, USYNC_THREAD, NULL)) #endif { printf("Can't initialize mutex\n"); exit(1); } /*Spawn threads*/ for(i=0;i<THREADS;i++) { params[i].ctx=ctx[i]; params[i].thread_id=i; printf("Thread %d... ",i); #ifdef DCE_THREADS if (pthread_create(&thread_id[i],pthread_attr_default, (pthread_startroutine_t)do_transaction, (pthread_addr_t) ¶ms[i])) #else if (status = thr_create (NULL, 0, do_transaction, ¶ms[i], 0, &thread_id[i])) #endif printf("Cant create thread %d\n",i); else printf("Created\n"); } /* Logoff sessions....*/ for(i=0;i<THREADS;i++) { /*wait for thread to end */ printf("Thread %d ....",i); #ifdef DCE_THREADS if (pthread_join(thread_id[i],&status)) printf("Error when waiting for thread % to terminate\n", i); else printf("stopped\n"); printf("Detach thread..."); if (pthread_detach(&thread_id[i])) printf("Error detaching thread! \n"); else printf("Detached!\n"); #else if (thr_join(thread_id[i], NULL, NULL)) printf("Error waiting for thread to terminate\n"); #endif printf("Stop Session %d....",i); logoff(ctx[i]); EXEC SQL CONTEXT FREE :ctx[i]; } /*Destroys mutex*/ #ifdef DCE_THREADS if (pthread_mutex_destroy(&mutex)) #else if (mutex_destroy(&mutex)) #endif { printf("Can't destroy mutex\n"); exit(1); } } /********************************************************************* * Function: do_transaction * * Description: This functions executes one transaction out of the * records array. The records array is 'managed' by * the get_transaction function. * * ********************************************************************/ #ifdef DCE_THREADS void do_transaction(params) #else void *do_transaction(params) #endif parameters *params; { struct sqlca sqlca; record_log *trx; sql_context ctx=params->ctx; /* Done all transactions ? */ while (trx_nr < (sizeof(records)/sizeof(record_log))) { get_transaction(&trx); EXEC SQL WHENEVER SQLERROR DO err_report(sqlca); EXEC SQL CONTEXT USE :ctx; printf("Thread %d executing transaction\n",params->thread_id); switch(trx->action) { case 'M': EXEC SQL UPDATE ACCOUNTS SET BALANCE=BALANCE+:trx->amount WHERE ACCOUNT=:trx->to_account; EXEC SQL UPDATE ACCOUNTS SET BALANCE=BALANCE-:trx->amount WHERE ACCOUNT=:trx->from_account; break; default: break; } EXEC SQL COMMIT; } } /***************************************************************** * Function: err_report * * Description: This routine prints out the most recent error * ****************************************************************/ void err_report(sqlca) struct sqlca sqlca; { if (sqlca.sqlcode < 0) printf("\n%.*s\n\n",sqlca.sqlerrm.sqlerrml,sqlca.sqlerrm.sqlerrmc); exit(1); } /***************************************************************** * Function: logon * * Description: Logs on onto the database as USERNAME/PASSWORD * *****************************************************************/ void logon(ctx,connect_info) sql_context ctx; char * connect_info; { EXEC SQL WHENEVER SQLERROR DO err_report(sqlca); EXEC SQL CONTEXT USE :ctx; EXEC SQL CONNECT :connect_info; printf("Connected!\n"); } /****************************************************************** * Function: logoff * * Description: This routine logs off the database * ******************************************************************/ void logoff(ctx) sql_context ctx; { EXEC SQL WHENEVER SQLERROR DO err_report(sqlca); EXEC SQL CONTEXT USE :ctx; EXEC SQL COMMIT WORK RELEASE; printf("Logged off!\n"); } /****************************************************************** * Function: get_transaction * * Description: This routine returns the next transaction to process * ******************************************************************/ void get_transaction(trx) record_log ** trx; { #ifdef DCE_THREADS if (pthread_mutex_lock(&mutex)) #else if (mutex_lock(&mutex)) #endif printf("Can't lock mutex\n"); *trx=&records[trx_nr]; trx_nr++; #ifdef DCE_THREADS if (pthread_mutex_unlock(&mutex)) #else if (mutex_unlock(&mutex)) #endif printf("Can't unlock mutex\n"); }
An OCI environment handle will be tied to the Pro*C/C++ runtime context, which is of the sql_context type introduced in Oracle 7.3. That is, one Pro*C/C++ runtime context maintained by SQLLIB during application execution will be associated with at most one OCI environment handle. Multiple database connections are allowed for each Pro*C/C++ runtime context, which will be associated to the OCI environment handle for the runtime context.
An EXEC SQL CONTEXT USE statement specifies a runtime context to be used in a Pro*C/C++ program. This context applies to all executable SQL statements that positionally follow it in a given Pro*C/C++ file until another EXEC SQL CONTEXT USE statement occurs. If no EXEC SQL CONTEXT USE appears in a source file, the default "global" context is assumed. Thus, the current runtime context, and therefore the current OCI environment handle, is known at any point in the program.
The runtime context and its associated OCI environment handle are initialized when a database logon is performed using EXEC SQL CONNECT in Pro*C/C++.
When a Pro*C/C++ runtime context is freed using the EXEC SQL CONTEXT FREE statement, the associated OCI environment handle is terminated and all of its resources, such as space allocated for the various OCI handles and LOB locators, are de-allocated. This command releases all other memory associated with the Pro*C/C++ runtime context. An OCI environment handle that is established for the default "global" runtime remains allocated until the Pro*C/C++ program terminates.
An OCI environment established through Pro*C/C++ will use the following parameters:
SQLLIB library provides routines to obtain the OCI environment and service context handles for database connections established through a Pro*C/C++ program. Once the OCI handles are obtained, the user can call various OCI routines, e.g. to perform client-side DATE arithmetic, execute navigational operations on objects etc. See Chapter 8, "Object Support in Pro*C/C++" for more details. These SQLLIB functions are described below, and their prototypes are available in the public header file sql2oci.h.
A Pro*C/C++ user who mixes embedded SQL and calls in the other Oracle programmatic interfaces must exercise reasonable care. For example, if a user terminates a connection directly using the OCI interface, SQLLIB state is out-of-sync; the behavior for subsequent SQL statements in the Pro*C/C++ program is undefined in such cases.
Starting with release 8.0, the new SQLLIB functions that provide interoperability with the Oracle8 OCI are declared in header file sql2oci.h:
SQL_SINGLE_RCTX, defined as zero when you include sql2oci.h, as the first parameter in either function, when using single-threaded runtime contexts.
The SQLLIB library function SQLEnvGet() (SQLIB OCI Environment Get) returns the pointer to the OCI environment handle associated with a given SQLLIB runtime context. The prototype for this function is:
sword SQLEnvGet(dvoid *rctx, OCIEnv **oeh);
where:
The SQLLIB library function SQLSvcCtxGet() (SQLIB OCI Service Context Get) returns the OCI service context for the Pro*C/C++ database connection. The OCI service context can then be used in direct calls to OCI functions. The prototype for this function is:
sword SQLSvcCtxGet(dvoid *rctx, text *dbname, sb4 dbnamelen, OCISvcCtx **svc);
where:
To embed OCI release 8 calls in your Pro*C/C++ program:
1. Include the public header sql2oci.h
2. Declare an environment handle (type OCIEnv *) in your Pro*C/C++ program:
OCIEnv *oeh;
3. Optionally, declare a service context handle (type OCISvcCtx *) in your Pro*C/C++ program if the OCI function you wish to call requires the ServiceContext handle.
OCISvcCtx *svc;
4. Declare an error handle (type OCIError *) in your Pro*C/C++ program:
OCIError *err;
5. Connect to Oracle using the embedded SQL statement CONNECT. Do not connect using OCI.
EXEC SQL CONNECT ...
6. Obtain the OCI Environment handle that is associated with the desired runtime context using the SQLEnvGet function.
For single-threaded applications:
retcode = SQLEnvGet(SQL_SINGLE_RCTX, &oeh);
or for multi-threaded applications:
sql_context ctx1; ... EXEC SQL CONTEXT ALLOCATE :ctx1; EXEC SQL CONTEXT USE :ctx1; ... EXEC SQL CONNECT :uid IDENTIFIED BY :pwd; ... retcode = SQLEnvGet(ctx1, &oeh);
7. Allocate an OCI error handle using the retrieved environment handle
retcode = OCIHandleAlloc((dvoid *)oeh, (dvoid **)err, (ub4)OCI_HTYPE_ERROR, (ub4)0, (dvoid **)0);
8. Optionally, if needed by the OCI call you use, obtain the OCIServiceContext handle using the SQLSvcCtxGet call:
For single-threaded applications:
retcode = SQLSvcCtxGet(SQL_SINGLE_RCTX, (text *)dbname, (ub4)dbnlen, &svc);
or, for multi-threaded applications:
sql_context ctx1; ... EXEC SQL ALLOCATE :ctx1; EXEC SQL CONTEXT USE :ctx1; ... EXEC SQL CONNECT :uid IDENTIFIED BY :pwd AT :dbname USING :hst; ... retcode = SQLSvcCtxGet(ctx1, (text *)dbname, (ub4)strlen(dbname), &svc);
Note: A null pointer may be passed as the dbname if the Pro*C/C++ connection is not named with an AT clause.
X/Open applications run in a distributed transaction processing (DTP) environment. In an abstract model, an X/Open application calls on resource managers (RMs) to provide a variety of services. For example, a database resource manager provides access to data in a database. Resource managers interact with a transaction manager (TM), which controls all transactions for the application.
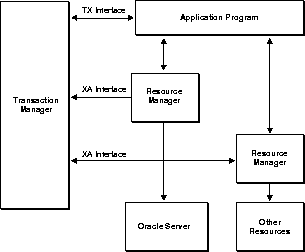
Figure 4-5 shows one way that components of the DTP model can interact to provide efficient access to data in an Oracle8 database. The DTP model specifies the XA interface between resource managers and the transaction manager. Oracle supplies an XA-compliant library, which you must link to your X/Open application. Also, you must specify the native interface between your application program and the resource managers.
The DTP model that specifies how a transaction manager and resource managers interact with an application program is described in the X/Open guide Distributed Transaction Processing Reference Model and related publications, which you can obtain by writing to
X/Open Company Ltd.
1010 El Camino Real, Suite 380
Menlo Park, CA 94025
For instructions on using the XA interface, see your Transaction Processing (TP) Monitor user's guide.
You can use the precompiler to develop applications that comply with the X/Open standards. However, you must meet the following requirements.
The X/Open application does not establish and maintain connections to a database. Instead, the transaction manager and the XA interface, which is supplied by Oracle, handle database connections and disconnections transparently. So, normally an X/Open-compliant application does not execute CONNECT statements.
The X/Open application must not execute statements such as COMMIT, ROLLBACK, SAVEPOINT, and SET TRANSACTION that affect the state of global transactions. For example, the application must not execute the COMMIT statement because the transaction manager handles commits. Also, the application must not execute SQL data definition statements such as CREATE, ALTER, and RENAME because they issue an implicit COMMIT.
The application can execute an internal ROLLBACK statement if it detects an error that prevents further SQL operations. However, this might change in later releases of the XA interface.
If you want your X/Open application to issue OCI calls, you must use the runtime library routine sqlld2(), which sets up an LDA for a specified connection established through the XA interface. For a description of the sqlld2() call, see the Programmer's Guide to the Oracle Call Interface. Note that the following OCI calls cannot be issued by an X/Open application: OCOM, OCON, OCOF, ONBLON, ORLON, OLON, OLOGOF.
For a discussion of how to use OCI Release 8 calls in Pro*C/C++, see "Interfacing to OCI Release 8" on page 4-56.
To get XA functionality, you must link the XA library to your X/Open application object modules. For instructions, see your system-specific Oracle8 documentation.