Release 8.0
A58246-01
Library |
Product |
Contents |
Index |
| Oracle8 Tuning Release 8.0 A58246-01 |
|
![]()
![]()
This section summarizes common tools and techniques you can use to obtain performance feedback on parallel operations.
See Also: Oracle8 Concepts, for basic principles of parallel execution.
See your operating system-specific Oracle documentation for more information about tuning while using parallel execution.
Use the decision tree in Figure 21-1 to diagnose parallel performance problems. Some key issues are the following:
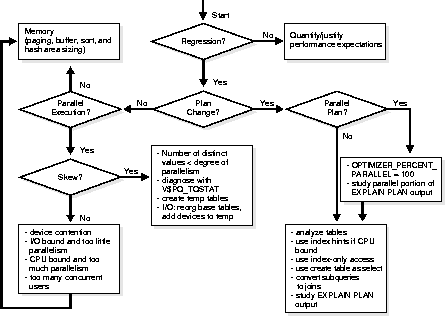
Does parallel execution's actual performance deviate from what you expected? If performance is as you expected, can you justify the notion that there is a performance problem? Perhaps you have a desired outcome in mind, to which you are comparing the current outcome. Perhaps you have a justifiable performance expectation which the system is not achieving. You might have achieved this level of performance or particular execution plan in the past, but now, with a similar environment and operation, this is not being met.
If performance is not as you expected, can you quantify the deviation? For data warehousing operations, the execution plan is key. For critical data warehousing operations, save the EXPLAIN PLAN results. Then, as you analyze the data, reanalyze, upgrade Oracle, and load in new data over the course of time, you can compare any new execution plan with the old plan. You can take this approach either proactively or reactively.
Alternatively, you may find that you get a plan that works better if you use hints. You may want to understand why hints were necessary, and figure out how to get the optimizer to generate the desired plan without the hints. Try increasing the statistical sample size: better statistics may give you a better plan. If you had to use a PARALLEL hint, look to see whether you had OPTIMIZER_PERCENT_PARALLEL set to 100%.
If there has been a change in the execution plan, determine whether the plan is (or should be) parallel or serial.
If the execution plan is (or should be) parallel:
See Also: Parallel EXPLAIN PLAN tags are defined in Table 23-2.
If the execution plan is (or should be) serial, consider the following strategies:
Note: Using different sample sizes can cause the plan to change. Generally, the higher the sample size, the better the plan.
If the cause of regression cannot be traced to problems in the plan, then the problem must be an execution issue. For data warehousing operations, both serial and parallel, consider memory. Check the paging rate and make sure the system is using memory as effectively as possible. Check buffer, sort, and hash area sizing. After you run a query or DML operation, you can look at the V$SESSTAT, V$PQ_SESSTAT and V$PQ_SYSSTAT views to see the number of server processes used, and other information for the session and system.
See Also: "Querying the Dynamic Performance Views: Example" on page 21-12
If parallel execution is occurring, is there unevenness in workload distribution (skew)? For example, if there are 10 CPUs and a single user, you can see whether the workload is evenly distributed across CPUs. This may vary over time, with periods that are more or less I/O intensive, but in general each CPU should have roughly the same amount of activity.
The statistics in V$PQ_TQSTAT show rows produced and consumed per parallel server process. This is a good indication of skew, and does not require single user operation.
Operating system statistics show you the per-processor CPU utilization and per-disk I/O activity. Concurrently running tasks make it harder to see what is going on, however. It can be useful to run in single-user mode and check operating system monitors which show system level CPU and I/O activity.
When workload distribution is unbalanced, a common culprit is the presence of skew in the data. For a hash join, this may be the case if the number of distinct values is less than the degree of parallelism. When joining two tables on a column with only 4 distinct values, you will not get scaling on more than 4. If you have 10 CPUs, 4 of them will be saturated but 6 will be idle. To avoid this problem, change the query: use temporary tables to change the join order such that all operations have more values in the join column than the number of CPUs.
If I/O problems occur you may need to reorganize your data, spreading it over more devices. If parallel execution problems occur, check to be sure you have followed the recommendation to spread data over at least as many devices as CPUs.
If there is no skew in workload distribution, check for the following conditions:
After analyzing your tables and indexes, you should be able to run operations and see speedup that scales linearly with the degree of parallelism used. The following operations should scale:
Start with simple parallel operations. Evaluate total I/O throughput with SELECT COUNT(*) FROM facts. Evaluate total CPU power by adding a complex WHERE clause. I/O imbalance may suggest a better physical database layout. After you understand how simple scans work, add aggregation, joins, and other operations that reflect individual aspects of the overall workload. Look for bottlenecks.
Besides query performance you should also monitor parallel load, parallel index creation, and parallel DML, and look for good utilization of I/O and CPU resources.
Use an EXPLAIN PLAN statement to view the sequential and parallel operation plan. The OTHER_TAG column of the plan table summarizes how each plan step is parallelized, and describes the text of the operation used by parallel server processes for each operation. Optimizer cost information for selected plan steps is given in the COST, BYTES, and CARDINALITY columns. Table 23-2 summarizes the meaning of the OTHER_TAG column.
EXPLAIN PLAN thus provides detailed information as to how specific operations are being performed. You can then change the execution plan for better performance. For example, if many steps are serial (where OTHER_TAG is blank, serial to parallel, or parallel to serial), then the parallel controller could be a bottleneck. Consider the following SQL statement, which summarizes sales data by region:
EXPLAIN PLAN SET STATEMENT_ID = `Jan_Summary' FOR SELECT dim_1 SUM(meas1) FROM facts WHERE dim_2 < `02-01-1995' GROUP BY dim_1
This script extracts a compact hierarchical plan from the EXPLAIN PLAN output:
SELECT SUBSTR( LPAD(' ',2*(level-1)) || DECODE(id, 0, statement_id, operation) || ' ' || options || ' ' || object_name || ' [' || partition_start || ',' || partition_stop || '] ' || other_tag, 1, 79) "step [start,stop] par" FROM plan_table START WITH id = 0 CONNECT BY PRIOR id = parent_id AND PRIOR NVL(statement_id,' ') = NVL(statement_id);
Following is the query plan for "Jan_Summary":
Jan_Summary [,] SORT GROUP BY [,] PARALLEL_TO_SERIAL TABLE ACCESS FULL facts [NUMBER(1),NUMBER(1)] PARALLEL_TO_PARALLEL;
Each parallel server scans a portion of the first partition of the facts table. All other partitions are pruned, as shown by the stop and start partition number.
Figure 21-2 illustrates how, with the PARALLEL_TO_PARALLEL keyword, data from the partitioned table is redistributed to a second set of parallel server processes for parallel grouping. Query server set 1 executes the table scan from the preceding example. The rows coming out are repartitioned through the table queue to parallel server set 2, which executes the GROUP BY operation. Because the GROUP BY operation indicates PARALLEL_TO_SERIAL, another table queue collects its results and sends it to the parallel coordinator, and then to the user.

As a rule, if the PARALLEL_TO_PARALLEL keyword exists, there will be two sets of parallel server processes. This means that for grouping, sort merge, or hash joins, twice the number of parallel server processes are assigned to the operation. This requires redistribution of data or rows from set 1 to set 2. If there is no PARALLEL_TO_PARALLEL keyword, then the operation gets just one set of servers. Such serial processes include aggregations, such as COUNT(*) FROM facts or SELECT * FROM facts WHERE DATE = '7/1/94'.
For non-distributed operations, the OBJECT_NODE column gives the name of the table queue. If the PARALLEL_TO_PARALLEL keyword exists, then the EXPLAIN PLAN of the parent operation should have SQL that references the child table queue in its FROM clause. In this way the plan describes the order in which the output from operations is consumed.
See Also: Chapter 23, "The EXPLAIN PLAN Command"
Dynamic performance views list internal Oracle8 data structures and statistics that you can query periodically to monitor progress of a long-running operation. When used in conjunction with data dictionary views, these tables provide a wealth of information. The challenge is visualizing the data and then acting upon it.
Note: On Oracle Parallel Server, global versions of these views aggregate the information over multiple instances. The global views have analogous names such as GV$FILESTAT for V$FILESTAT, and so on.
See Also: Oracle8 Parallel Server Concepts & Administration for more information about global dynamic performance views.
This view sums read and write requests, number of blocks, and service times for every datafile in every tablespace. It can help you diagnose I/O problems and workload distribution problems.
The file numbers listed in V$FILESTAT can be joined to those in the DBA_DATA_FILES view to group I/O by tablespace or to find the filename for a given file number. By doing ratio analysis you can determine the percentage of the total tablespace activity used by each file in the tablespace. If you make a practice of putting just one large, heavily accessed object in a tablespace, you can use this technique to identify objects that have a poor physical layout.
You can further diagnose disk space allocation problems using the DBA_EXTENTS view. Ensure that space is allocated evenly from all files in the tablespace. Monitoring V$FILESTAT during a long-running operation and correlating I/O activity to the EXPLAIN PLAN output is a good way to follow progress.
This view lists the name, current value, and default value of all system parameters. In addition, the view indicates whether the parameter may be modified online with an ALTER SYSTEM or ALTER SESSION command.
This view is valid only when queried from a session that is executing parallel SQL statements. Thus it cannot be used to monitor a long running operation. It gives summary statistics about the parallel statements executed in the session, including total number of messages exchanged between server processes and the actual number of parallel server processes used.
This view tallies the current and total CPU time and number of messages sent and received per parallel server process. It can be monitored during a long-running operation. Verify that there is little variance among processes in CPU usage and number of messages processed. A variance may indicate a load-balancing problem. Attempt to correlate the variance to a variance in the base data distribution. Extreme imbalance could indicate that the number of distinct values in a join column is much less than the degree of parallelism. See "Parallel CREATE TABLE ... AS SELECT" in Oracle8 Concepts for a possible workaround.
The V$PQ_SYSSTAT view aggregates session statistics from all parallel server processes. It sums the total parallel server message traffic, and gives the status of the pool of parallel server processes.
This view can help you determine the appropriate number of parallel server processes for an instance. The statistics that are particularly useful are "Servers Busy", "Servers Idle", "Servers Started", and "Servers Shutdown".
Periodically examine V$PQ_SYSSTAT to determine whether the parallel server processes for the instance are actually busy, as follows:
SELECT * FROM V$PQ_SYSSTAT WHERE statistic = "Servers Busy"; STATISTIC VALUE --------------------- ----------- Servers Busy 70
This view provides a detailed report of message traffic at the level of the table queue. It is valid only when queried from a session that is executing parallel SQL statements. A table queue is the pipeline between parallel server groups or between the parallel coordinator and a parallel server group or between a parallel server group and the coordinator. These table queues are represented in the plan by the tags PARALLEL_TO_PARALLEL, SERIAL_TO_PARALLEL, or PARALLEL_TO_SERIAL, respectively.
The view contains a row for each parallel server process that reads or writes each table queue. A table queue connecting 10 consumers to 10 producers will have 20 rows in the view. Sum the bytes column and group by TQ_ID (table queue identifier) for the total number of bytes sent through each table queue. Compare this with the optimizer estimates; large variations may indicate a need to analyze the data using a larger sample.
Compute the variance of bytes grouped by TQ_ID. Large variances indicate workload imbalance. Drill down on large variances to determine whether the producers start out with unequal distributions of data, or whether the distribution itself is skewed. The latter may indicate a low number of distinct values.
For many of the dynamic performance views, the system parameter TIMED_STATISTICS must be set to TRUE in order to get the most useful information. You can use ALTER SYSTEM to turn TIMED_STATISTICS on and off dynamically.
See Also: Chapter 22, "The Dynamic Performance Views"
The V$SESSTAT view provides statistics related to parallel execution for each session. The statistics include total number of queries, DML and DDL statements executed in a session and the total number of intra- and inter-instance messages exchanged during parallel execution during the session.
V$SYSSTAT does the same as V$SESSTAT for the entire system.
The following example illustrates output from two of these views:
SQLDBA> update /*+ parallel (iemp, 2) */ iemp set empno = empno +1; 91 rows processed. SQLDBA> commit; Statement processed. SQLDBA> select * from v$pq_sesstat; STATISTIC LAST_QUERY SESSION_TOTAL ------------------------------ ---------- ---------- Queries Parallelized 0 0 DML Parallelized 1 2 DFO Trees 1 2 Server Threads 2 0 Allocation Height 2 0 Allocation Width 0 0 Local Msgs Sent 34 60 Distr Msgs Sent 0 0 Local Msgs Recv'd 34 60 Distr Msgs Recv'd 0 0 11 rows selected. SQLDBA> select * from v$pq_sysstat; STATISTIC VALUE ------------------------------ ---------- Servers Busy 0 Servers Idle 2 Servers Highwater 2 Server Sessions 4 Servers Started 2 Servers Shutdown 0 Servers Cleaned Up 0 Queries Initiated 0 DML Initiated 2 DFO Trees 2 Local Msgs Sent 60 Distr Msgs Sent 0 Local Msgs Recv'd 60 Distr Msgs Recv'd 0 15 rows selected.
In V$PQ_SESSTAT, some of the statistics provide the following information.
In V$PQ_SYSSTAT, the "DML Initiated" statistic indicates the number of DML operations done in the system.
Note that statements such as INSERT ... SELECT are treated as a single DML statement, not as one DML statement and one query.
See Also: Oracle8 SQL Reference for information about statistics.
There is considerable overlap between information available in Oracle and information available though operating system utilities (such as sar and vmstat on UNIX-based systems). Operating systems provide performance statistics on I/O, communication, CPU, memory and paging, scheduling, and synchronization primitives. The Oracle V$SESSTAT view provides the major categories of OS statistics as well.
Typically, Operating system information about I/O devices and semaphore operations is harder to map back to database objects and operations than is Oracle information. However, some operating systems have good visualization tools and efficient means of collecting the data.
Operating system information about CPU and memory usage is very important for assessing performance. Probably the most important statistic is CPU usage. The goal of low -level performance tuning is to become CPU bound on all CPUs. Once this is achieved, you can move up a level and work at the SQL level to find an alternate plan that might be more I/O intensive but uses less CPU.
Operating system memory and paging information is valuable for fine tuning the many system parameters that control how memory is divided among memory-intensive warehouse subsystems like parallel communication, sort, and hash join.
If the system requires ten minutes to run an operation, it will take at least 10 minutes to roll back the operation: this is the best performance achievable. If there is some instance failure and some system failure, then recovery time will increase because not all the server processes are available to provide rollback.
You must either commit or roll back directly after you issue a parallel INSERT, UPDATE, or DELETE statement, or a serial insert with the APPEND hint. You can perform no other SQL commands until this is done.
Discrete transactions are not supported for parallel DML.
A session that is enabled for parallel DML may put transactions in the session in a special mode. If any DML statement in a transaction modifies a table in parallel, no subsequent serial or parallel query or DML statement can access the same table again in that transaction. This means that the results of parallel modifications cannot be seen during the transaction.
A complete listing of parallel DML and direct-load insert restrictions is found in Oracle8 Concepts. If a parallel restriction is violated, the operation is simply performed serially. If a direct-load insert restriction is violated, then the APPEND hint is ignored and a conventional insert is performed. No error message is returned.