
I am an Associate Professor in the Department of Electrical and Computer Engineering and an affiliated faculty member of the McGowan Institute of Regenerative Medicine at University of Pittsburgh. I direct the Pitt Intelligent System Laboratory (ISL). The source codes, datasets and other research artifacts made by my research team can also be found at our GitHub repository.
My research is positioned at the intersection among AI, computer systems and computer vision. It focuses on the design and deployment of multimodal generative AI and on-device AI systems, architectures and algorithms. I have strong interests in unveiling analytical principles underneath practical AI deployment problems, and designing systems based on these principles. The developed AI and system solutions are widely applied to different practical applications, including smart health, Internet of Things and edge computing. My research areas mainly include the following:
- Multimodal generative AI
- Spatial intelligence - perception, reasoning and action
- On-device AI
- Mobile and connected health
- Mobile and embedded computing systems
Note: I am currently looking for strong and self-motivated students with an interest in the above areas. If you are interested in my research and working with me, please send me email with your CV and transcripts. You can find more details about my research here, and a list of my recent publications here.
Professional Services
- I serve as the General Chair of 2026 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), which will be held in Pittsburgh in the first week of August 2026. IEEE/ACM CHASE is the premier conference in smart and connected health applications and systems. Please consider submitting your work! Submission deadline is January 26, 2026.
- I serve as the General Chair of HotMobile 2025. This is a great venue for people to share and discuss their preliminary but pioneering research ideas. Please consider submitting your work! Submission deadline is October 11, 2024.
- I serve as the Artifact Evaluation Co-Chair of ACM MobiCom 2024 and ACM MobiSys 2024. Details of submitting research artifacts will be soon posted on the conference websites. Please consier submitting the research artifacts of your accepted papers and being awarded with ACM Reproducibility Badges!
- I serve as the publicity co-chair of the 2023 ACM Conference on Embedded Networked and Sensor Systems (SenSys). SenSys 2023 will be held in Istanbul, Turkey, on November 13-15, 2023. The paper submission deadline is June 29, 2023. Please consider submitting your work!
- I serve as the TPC Co-Chair of the 2023 IEEE/ACM Int'l Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE). CHASE 2023 will be held as part of the ACM Federated Computing Research Conference (FCRC 2023) in June 16-23, 2023 in Orlando, Florida, together with other 10 top ACM conferences, including e-Energy’23, HPDC’23, ISCA’23, IWQoS’23, PADS’23, PLDI’23, PODC’23, SIGMETRICS’23, SPAA’23, and STOC’23. Submission deadline has been extended to December 23, 2022. Please consider submitting your work!
- I am co-chairing the 7th Mobile App Competition in conjunction with ACM MobiCom'22. The competition is for novel and innovative mobile applications that can be developed for any truly mobile device such as a smartphone, tablet, wearable, or a non-tethered AR/VR device. They can be built on any software platform including Android, iOS, Tizen, Windows, Harmony OS, Blackberry OS 10, and HTML5. Submission deadline is August 29, 2022. Please consider submitting your exciting mobile app designs!
Research Highlights
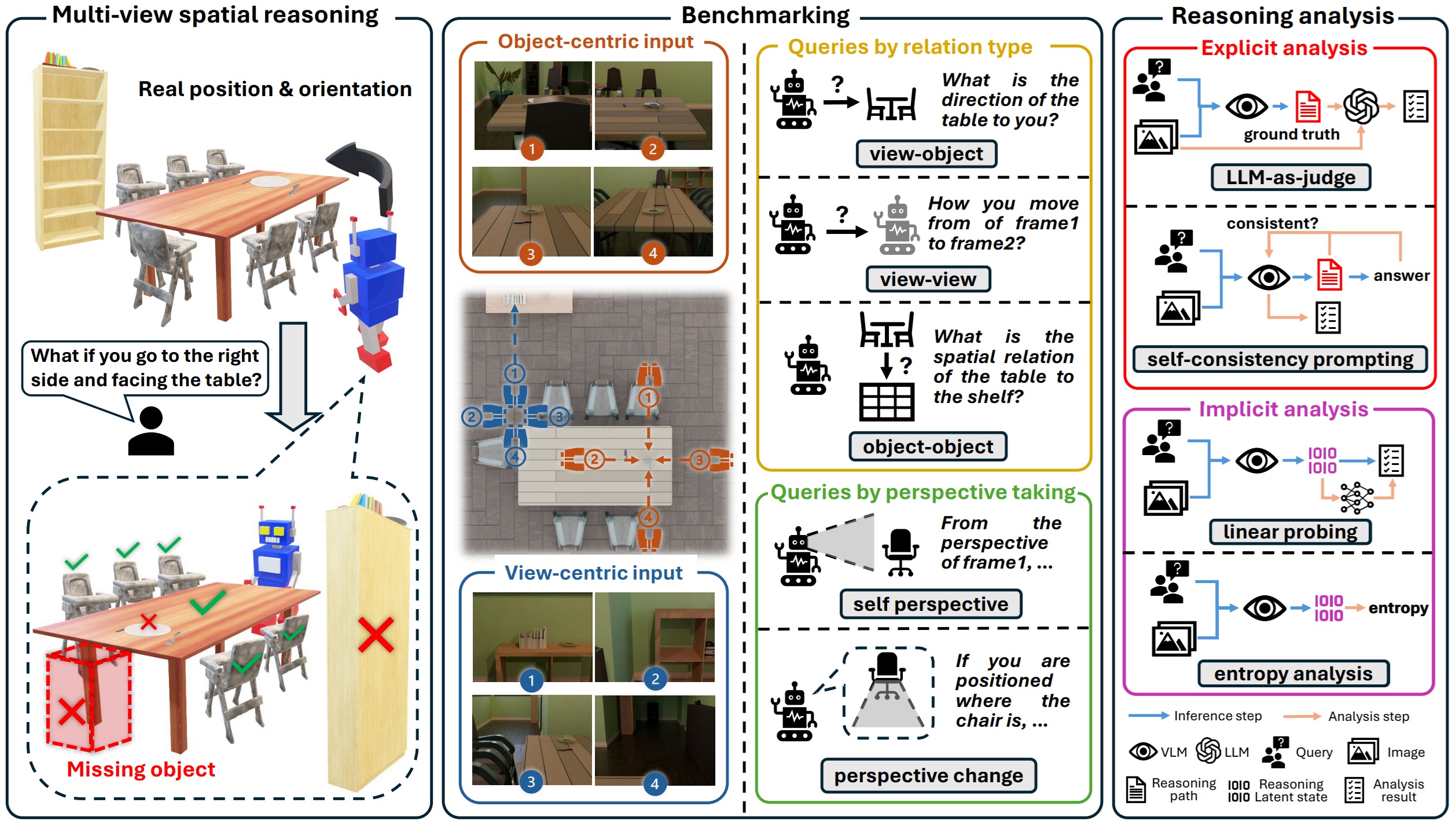
December 2025: Built on InfiniBench, we further analyzed current vision-language models (VLMs) on multi-view visual spatial reasoning tasks, which require VLMs' geometric coherence and cross-view consistency. We first developed ReMindView-Bench, a cognitively grounded benchmark for evaluating how VLMs construct, align and maintain spatial mental models across complementary viewpoints, and used it to reval current VLMs' consistent failures in cross-view alignment and perspective taking. We further conducted explicit and implicit analysis on VLMs' failures, by drawing on cognitive science theories about humans' spatial perception and reasoning, to ensure that the spatial factors we model and analyze reflect human understanding of the physical world. We found that VLMs remain reliable in early perceptual encoding but degrade sharply in later inference, and entropy trajectories reveal rising uncertainty and poor calibration in later phases. These results expose fundamental weakness in VLMs' cross-view geometric alignment, stable inference progression, and confidence calibration, calling for cognitively grounded training strategies to improve spatial reasoning. Check our paper here. |
 |
December 2025: Spatial intelligence is important in the emerging vision and embodied AI tasks, but vision-language models (VLMs) are known to perform poorly in spatial recognition and reasoning tasks, especially in 3D scenes with high complexity. To understand the VLM's limitations of spatial reasoning is a big challenge, because they need benchmarks that are not only diverse and scalable but also fully customizable. Benchmarks should enable full isolation and flexible manipulation of scene properties, such as object density, relative positioning and levels of occlusion levels, through configurable parameters within a large combinatorial space. Existing benchmarks face limitations in such customizablility, scalability, and semantic richness. To address these limitations, we developed InfiniBench, a fully automated, customizable and user-friendly benchmark generator that can synthesize a theoretically infinite variety of 3D scenes with parameterized control on scene complexity. InfiniBench translates scene descriptions in natural language into photo-realistic videos with complex and physically plausible 3D layouts, and outperforms SOTA 3D generation methods in prompt fidelity and physical plausibility, especially in high-complexity scenarios. Check our paper to appear at CVPR 2026 here. |
 |
November 2025: Spatial intelligence is the next frontier of AI, as it represents a new paradigm of perceiving and reasoning the 3D physical world, which calls for true imitation of human cognition and is hence fundamentally different from natural language tasks performed by traditional transformer-based Large Language Models. The capability of such 3D spatial perception and reasoning has been considered as the cornerstone of emerging areas, including embodied AI, world model/simulator, and further AGI. In our recent survey paper, we presented new insights about how AI model's spatial perception and reasoning correspond to different aspects of humans' cognitive functions and spatial mental modeling, including 1) the frame of reference used to anchor spatial relations, 2) the type of information being processed, and 3) the nature of task being performed. Such correspondence further results in a cognition-based taxonomy of spatial reasoning tasks, paired with a set of variant levels of reasoning complexity and difficulty. We also categorize the current methods of improving spatial reasoning capabilities into training-based and inference-based, and conclude that allowing the LLM/VLM to discover the proper 3D representation, either implicitly or explicitly, is the key to addressing the mismatch between the model's discrete linguistic encoding and continuous spatial encoding, allowing effective solutions to the representation-level spatial grounding problem. We would be excited in any discussions and explorations into this promising yet under-explored horizon that would further push the next frontier of AI! |
 |
July 2025: Our collaborative work with the Pitt School of Health and Rehabilitation Sciences, named ProGait: A Multi-Purpose Video Dataset and Benchmark for Transfemoral Prosthesis Users, has been accepted for publication at the International Conference on Computer Vision (ICCV), 2025. This paper introduces a multi-purpose dataset, namely ProGait, that includes 412 video clips from four above-knee amputees when testing multiple newly-fitted prosthetic legs through walking trials. This dataset depicts the presence, contours, poses, and gait patterns of human subjects with transfemoral prosthetic legs, and is hence designed to enable multiple vision tasks, including video object segmentation, 2D human pose estimation and gait analysis, over this practically important but currently ignored cohort of human subjects. This work also presented benchmark tasks and fine-tuned baseline models to illustrate the practical application and performance of the ProGait dataset, which can help human rehabilitation and medical robotics research in many ways. Check our paper here, the ProGait dataset here, and the source codes of benchmark tasks here. |
 |
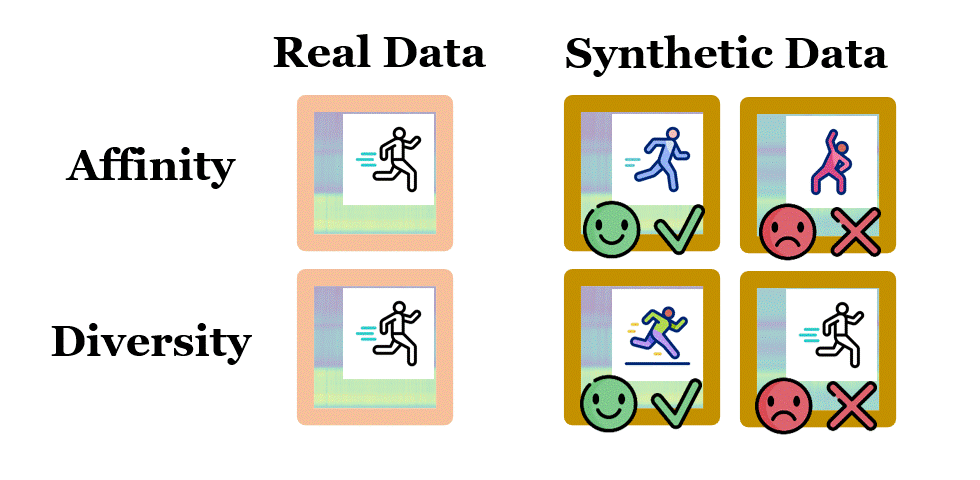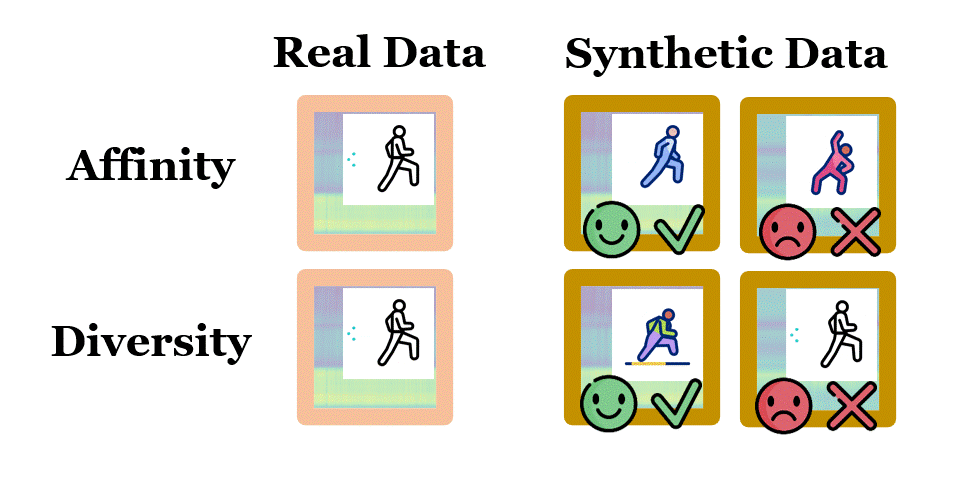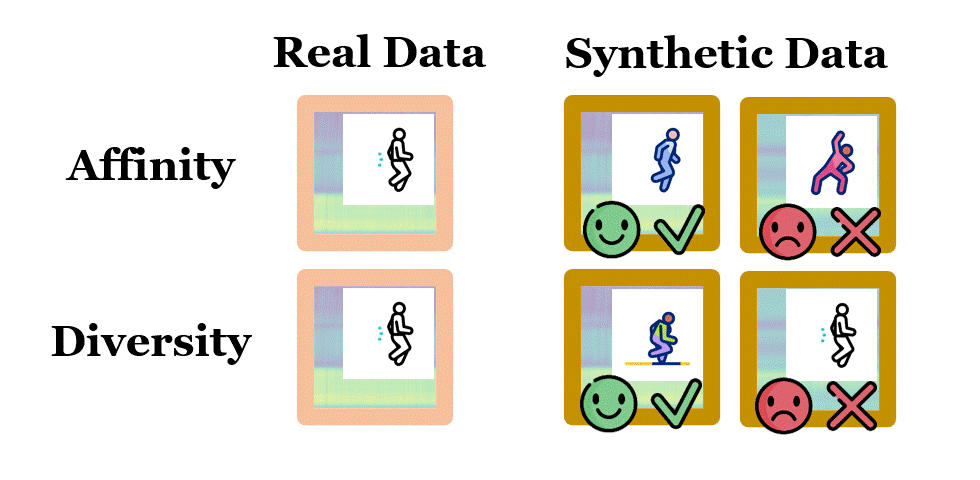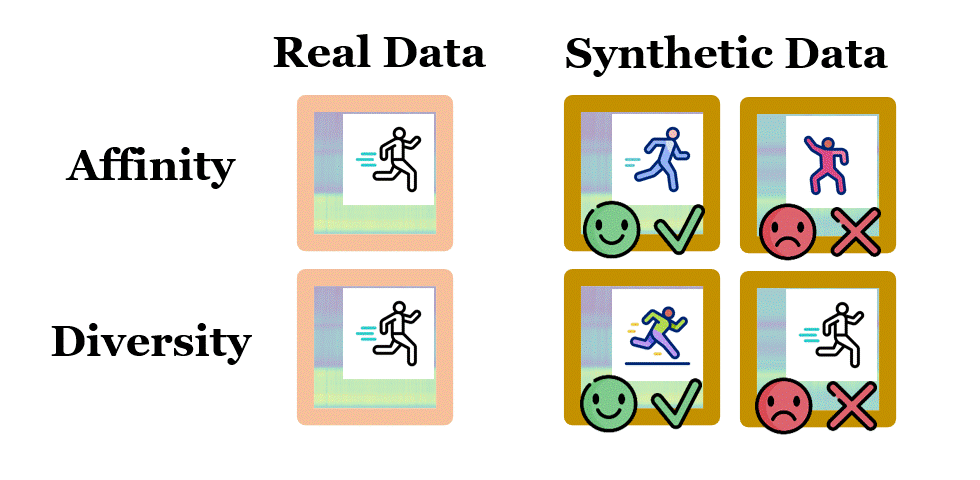
June 2025: Our paper, Data can Speak for Itself: Quality-guided Utilization of Wireless Synthetic Data, has been accepted for publication at the 2025 ACM International Conference on Mobile Systems, Applications, and Services (MobiSys) and won the Best Paper Award. In this paper, we focus on how to properly assess the quality of synthetic wireless data, which is generated by generative AI models and used to train other AI models for wireless sensing, network prediction, channel optimization and spectrum allocation. We proposed two tractable and generalizable metrics, namely affinity and diversity, for such quality assessment, and revealed that existing methods fail to ensure the affinity of wireless data they synthesized, due to lack of awareness of untrained conditions and domain-specific processing. We further designed SynCheck, a quality-guided synthetic data utilization technique that refines synthetic data quality during task model training. We believe that this work brings new insights about how AI can be effectively used for wireless research, and makes the first step towards creating high-quality wireless data for physical-grounded AI, embodied AI and AI for science. Check our paper here and the source codes here. |
 |
| April 2025: Our paper, Never Start from Scratch: Expediting On-Device LLM Personalization via Explainable Model Selection, has been accepted for publication at the 2025 ACM International Conference on Mobile Systems, Applications, and Services (MobiSys). This paper presents a completely new and innovative method of improving the compute efficiency of LLM personalization on resource-constrained personal mobile devices (e.g., smartphones), by utilizing the already personalized LLMs (pLLMs) computed at other users' devices instead of starting the personalization from scratch. To ensure appropriate selection of pLLMs for further personalization, our technique, namely XPerT (eXplainable Personalized Tuning), provides full explainability in natural language about how each pLLM has been personalized, in different aspects such as different language styles and image generation styles. Our experiments on multiple LLM families and text/image generation datasets show that XPerT's explainability achieves 96% accuracy of pLLM selection, and such accurate selection allows up to 83% reduction of wall-clock compute time and 51% improvement of data efficiency in LLM personalization, when tested on multiple Android smartphone models. Check our paper here. |  |
| February 2025: Text-to-video (T2V) generative AI could revolutionize many current and emerging application and industry domains. However, the capabilities of today's T2V generative models are mostly data dependent. While they perform well in domains covered by the training data, they usually fail to obey the real-world common knowledge and physical rules with out-of-distribution prompts. Expanding the model's capabilities, on the other hand, relies on large amounts of real-world data and is hence not scalable. Our recent work aims to address this limitation of data dependency, by fully unleashing the current T2V models' potential in scene generation given proper and detailed prompts. Our approach, namely PhyT2V, is a training-free technique that leverages the LLM's capabilities of chain-of-thought and step-back reasoning in the language domain, to logically identify the deficiency of generated videos and iteratively refine the current T2V models' video generation by correcting such deficiency with more precise and well articulated prompts. Check our source codes here, and our paper published at CVPR 2025 here. We have also released a Discord Bot which allows you to try our work with SOTA T2V models. | 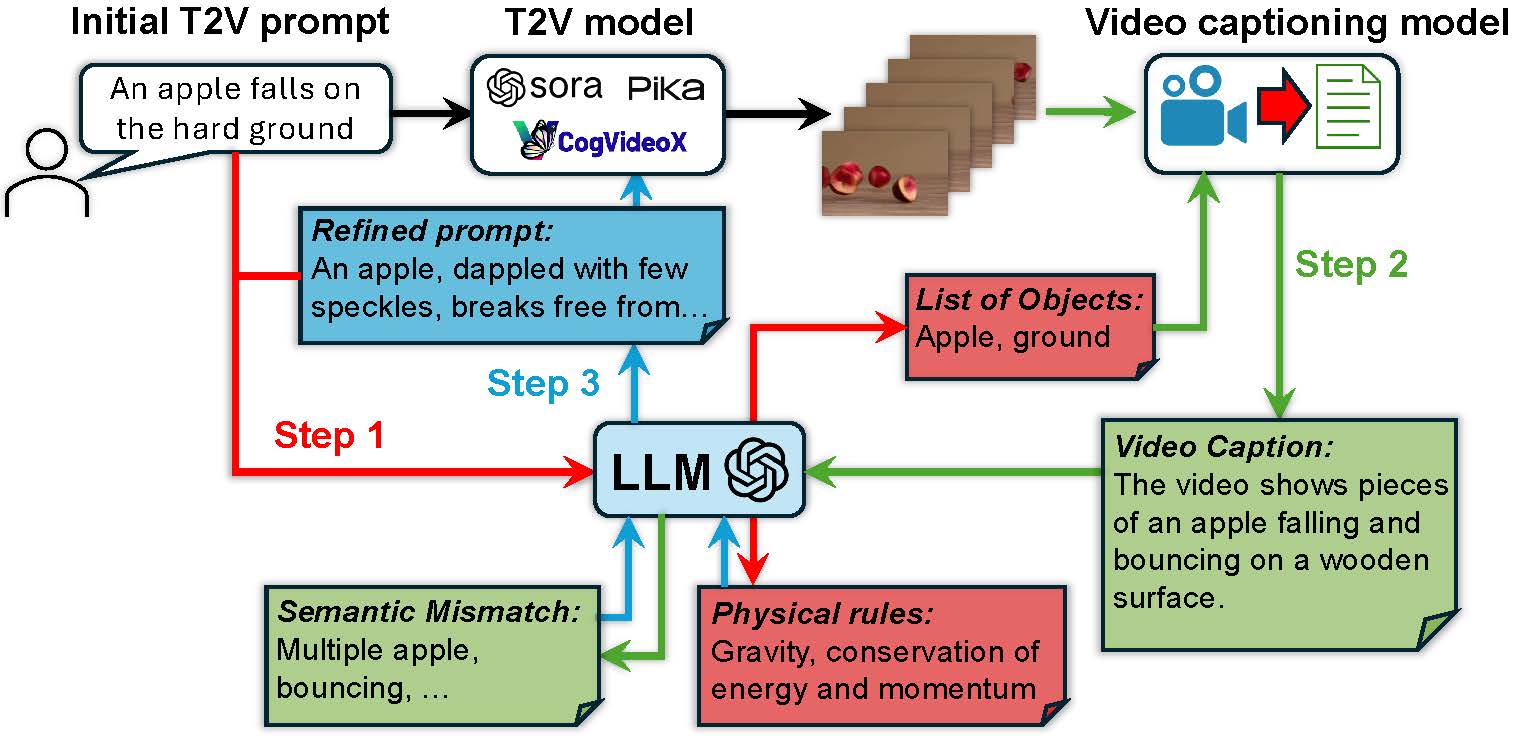 |
December 2024: Our paper, When Device Delays Meet Data Heterogeneity in Federated AIoT Applications, has been accepted for publication at the 2025 ACM International Conference on Mobile Computing and Networking (MobiCom). This paper targets a unique system-driven research problem when applying federated learning (FL) in practical AIoT systems. That is, heterogeneous types of AIoT devices cause data heterogeneity and varying amounts of device staleness, but existing FL frameworks improperly consider the impact of device delays (a.k.a., staleness) as independent from data heterogeneity. Instead, we explore a scenario where device delays and data |
 |
| December 2024: Our paper, Modality Plug-and-Play: Runtime Modality Adaptation in LLM-Driven Autonomous Mobile Systems, has been accepted for publication at the 2025 ACM International Conference on Mobile Computing and Networking (MobiCom). This is the first work that allows multimodal LLMs to elastically switch between input data modalities at runtime, for embodied AI applications such as autonomous navigation. Our basic technical approach is to use fully trainable projectors to adaptively connect the unimodal data encoders being used to a flexible set of last LLM blocks. In this way, we can flexibly adjust the amount of LLM blocks being connected to balance between accuracy of runtime fine-tuning cost, and optimize the efficiency of cross-modal interaction by controlling the amount of information being injected in each connection. Our implementations on NVidia Jetson AGX Orin demonstrate short modality adaptation delays of few minutes with mainstream LLMs, 3.7x fine-tuning FLOPs reduction, and 4% accuracy improvements on multimodal QA tasks. Check the source codes of our work here and the paper here. |  |
| August 2024: Our paper, Perceptual-Centric Image Super-Resolution using Heterogeneous Processors on Mobile Devices, has been accepted for publication at the 2024 ACM International Conference on Mobile Computing and Networking (MobiCom). It focuses on using heterogeneous processors on mobile devices to accelerate the computationally expensive image super-resolution, while minimizing the impact of AI accelerators' reduced arithmetic precision on the images' perceptual quality. Check our paper here. | 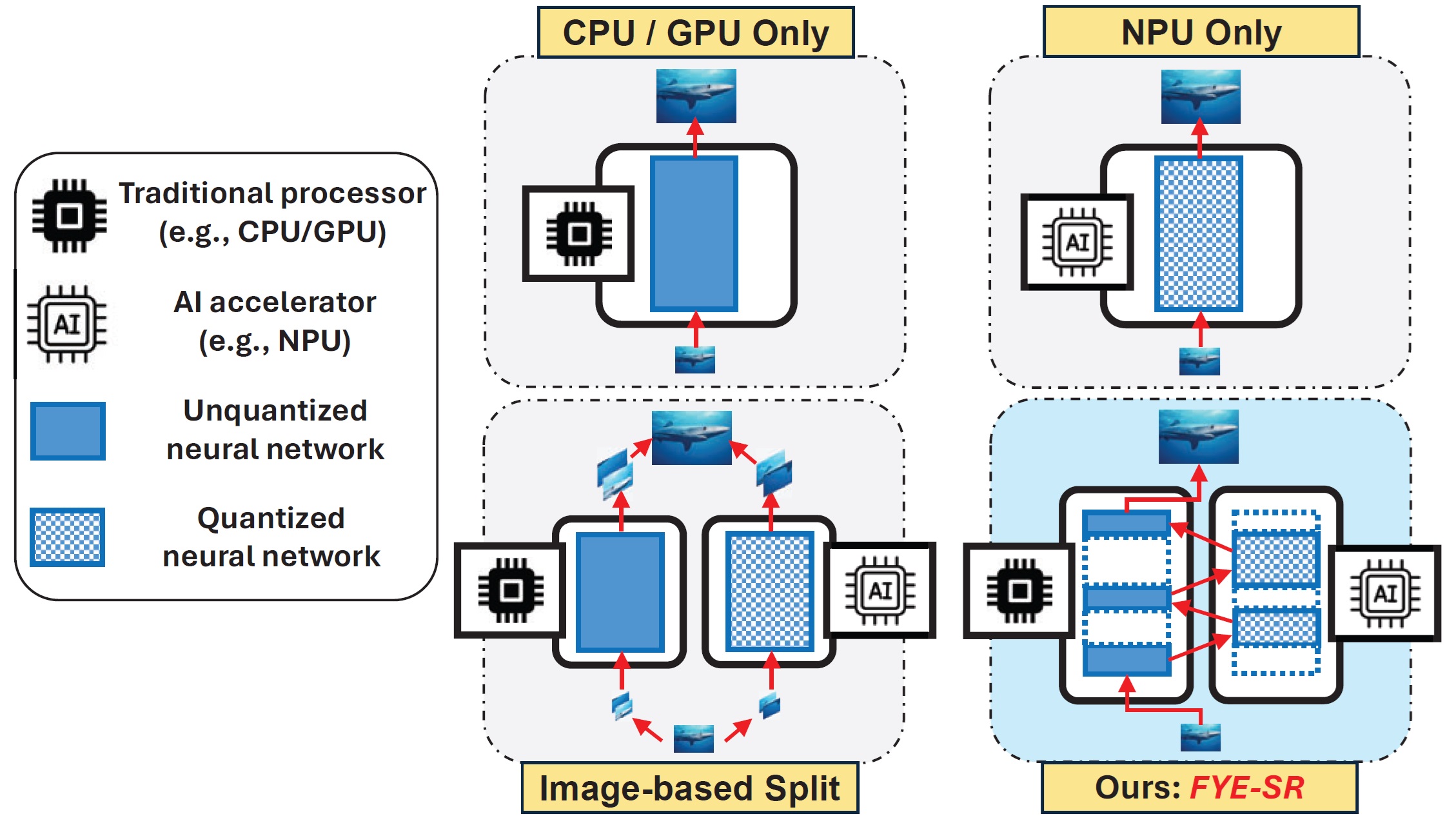 |
| May 2024: Being different from model compression that requires expensive retraining, sparse activation can effectively reduce neural network models' inference cost at runtime without any prior retraining or adaptation efforts. Although sparse activation has been proved to be effective on Large Language Models (LLMs) that are usually redundant (e.g., OPT and BLOOMZ models), its applicability on recent Small Language Models (SLMs) with higher parameter efficiency remains questionable. Our recent work verified such possibility by using gradient-based attribution scores to evaluate neurons' importance in inference, in both analytical and experimental perspectives. Our results show that we can achieve up to 80% sparsity in major SLM models, including Phi-1.5/2 and MobiLlama-0.5B/1B, with less than 5% model accuracy loss on QA tasks. Check our preprint and source codes. | 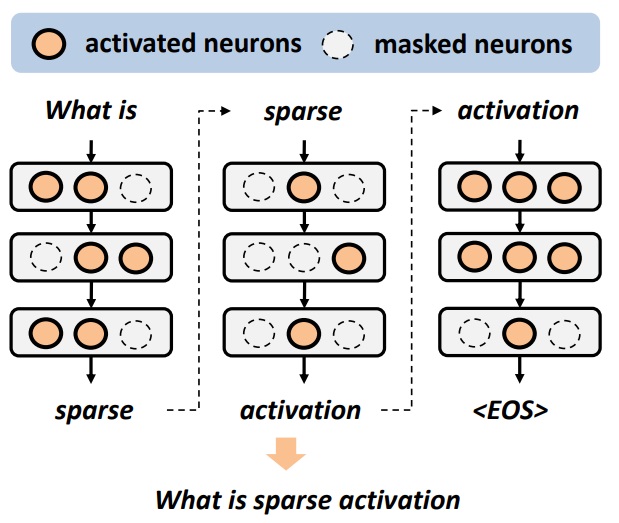 |
| May 2024: Illegally using fine-tuned diffusion models to forge human portraits has been a major threat to trustworthy AI. While most existing work focuses on detection of the AI-forged contents, our recent work instead aims to mitigate such illegal domain adaptation by applying safeguards on diffusion models. Being different from model unlearning techniques that cannot prevent the illegal domain knowledge from being relearned with custom or public data, our approach, namely FreezeGuard, suggests that the model publisher selectively freezes tensors in pre-trained models that are critical to the convergence of fine-tuning in illegal domains. FreezeAsGuard can effectively reduce the quality of images generated in illegal domains and ensure that these images are unrecognizable as target objects. Meanwhile, it has the minimum impact on legal domain adaptations, and can save up to 48% GPU memory and 21% wall-clock time in model fine-tuning. Check our preprint and source codes. |  |
| April 2024: We are pleased to release our recently completed Generative AI Tutorial and Roadmap, which is a detailed learning guide for generative AI research, including a curated list of state-of-the-art research articles, projects, open-sourced code repositories, and other related research resources. This tutorial covers a wide range of well studied, currently popular and emerging research topics in the broaderly defined area of generative AI, and can be used as both learning materials for entry-level graduate students and reference documents for other researchers. We will also continuously update this tutorial to add new contents and topics. Please stay tuned! |  |
| January 2024: We are happy to publish the dataset of human airway measurements, produced by our integrated AI and sensing systems for smart pulmonary telemedicine, namely Acoustic Waveform Respiratory Evaluation (AWARE). This dataset contains airway measurements of 382 human subjects, including patients with various pulmonary diseases and healthy control subjects, recruited from the Children's Hospital of Pittsburgh during the past 3 years. The contents of the dataset include raw WAV files from acoustic sensing, segmented and aligned acoustic signal pulses, and processed measurements of airway cross-sectional areas. More details can be found in dataset page and source codes of using the dataset can be found here. To our best knowledge, this is the first public dataset of human airway measurements with pulmonary diseases, and we welcome any feedback from the smart health research community. | 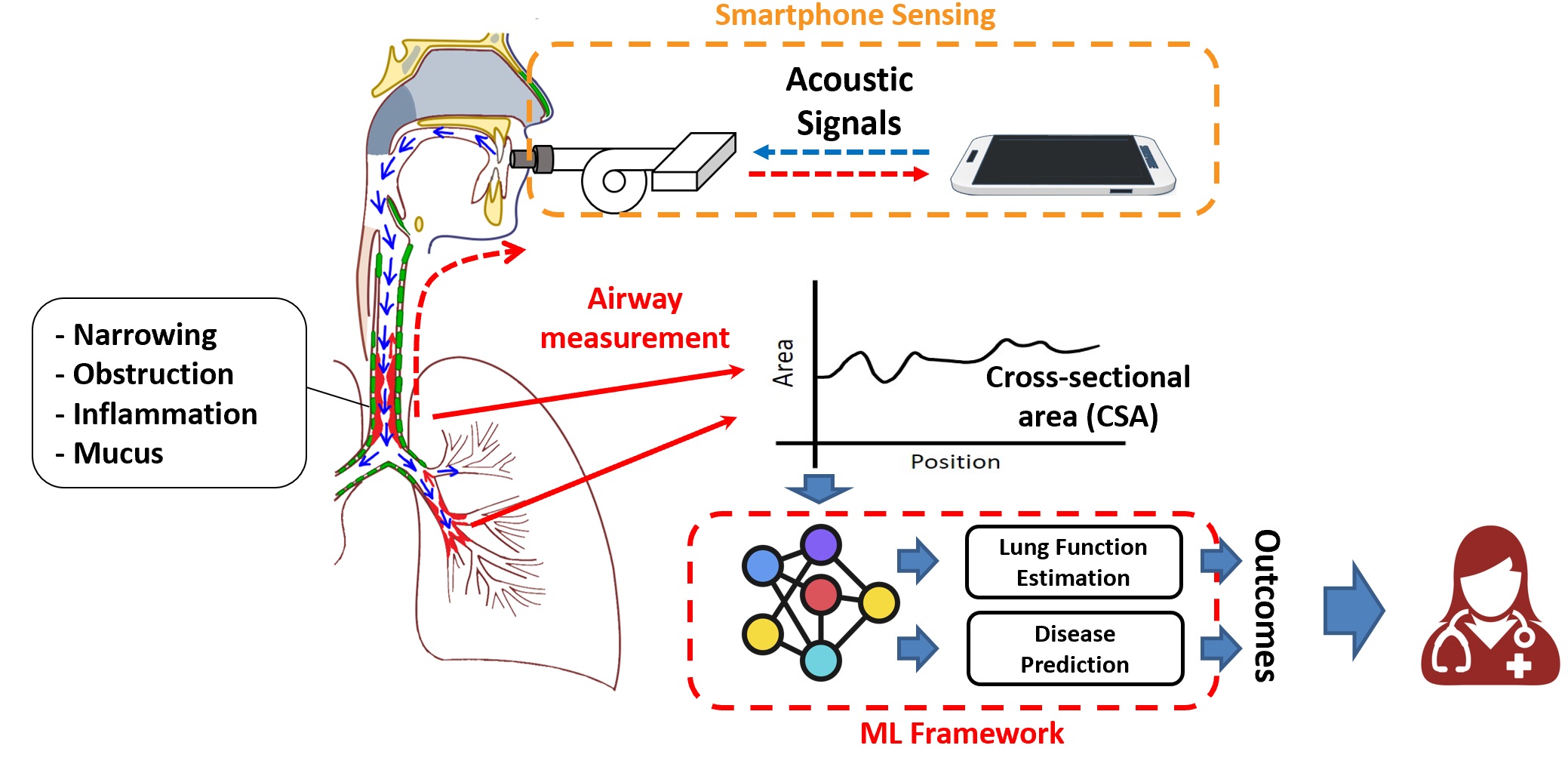 |
| January 2024: Our paper, Towards Green AI in Fine-Tuning Large Language Models via Adaptive Backpropagation, has been accepted for publication at the 2024 International Conference on Learning Representations (ICLR). It focuses on computationally efficient LLM fine-tuning, and reduces the FLOPs of LLM fine-tuning by 30% and improves the model accuracy by 4%, compared to LoRA. Check our paper here. | 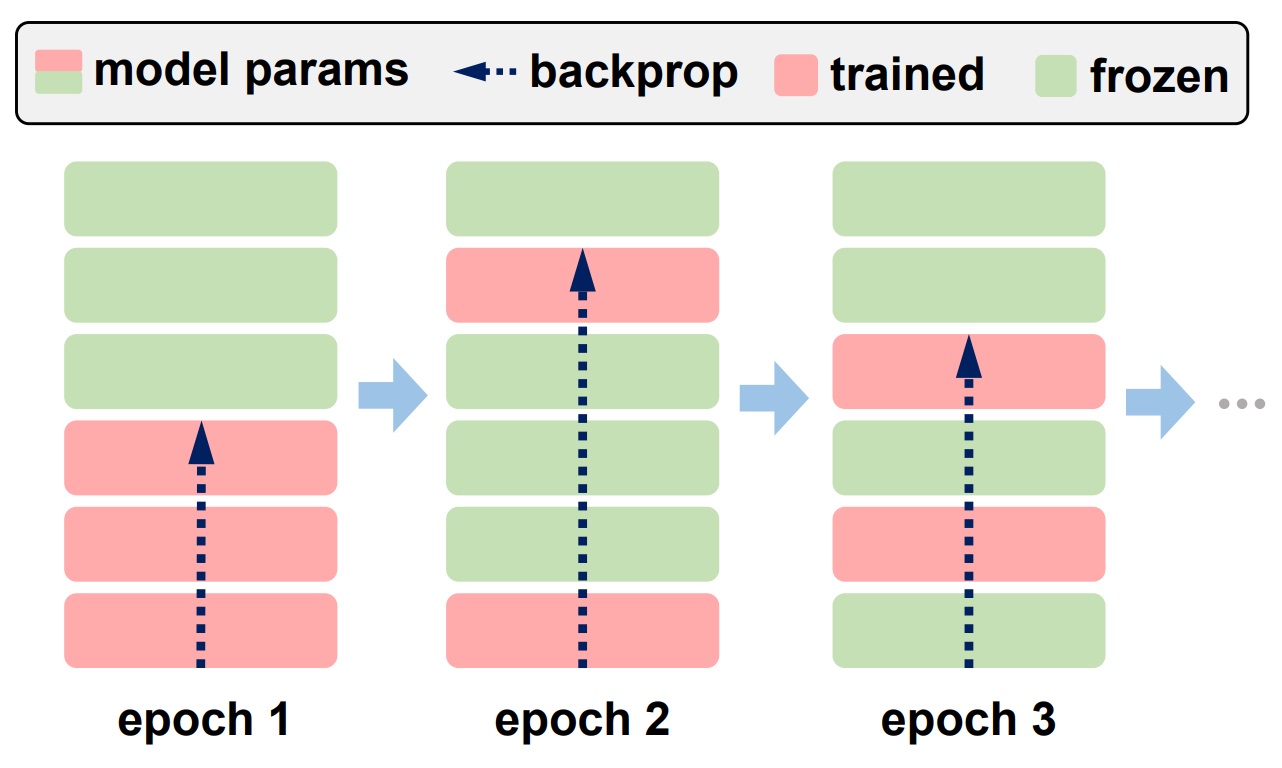 |
| October 2023: Since 2020, our integrated AI and sensing systems for smart pulmonary telemedicine, namely PTEase, have been applied to and tested on more than 400 patients with various pulmonary diseases at the Children's Hospital of Pittsburgh, for remote disease diagnosis, evaluation and management, and have particularly helped families in various minority groups with limited access to healthcare. Please see the table for demographics of involved human subjects. By applying on-device AI models and ML algorithms on patient data collected on smartphones, we can achieve 75% accuracy on diagnosing pulmonary diseases in diverse patient groups and 11%-15% errors in estimating lung function indices. Check our recent paper for details. Currently, we are in ongoing processes of commercializing these techniques and clinical studies at larger populations, by applying for FDA 510(k) clearances on medical device use and licensing our techniques to both US and international companies. Check this website for latest news and this page for more details on our research of integrated AI and sensing systems for smart health. | 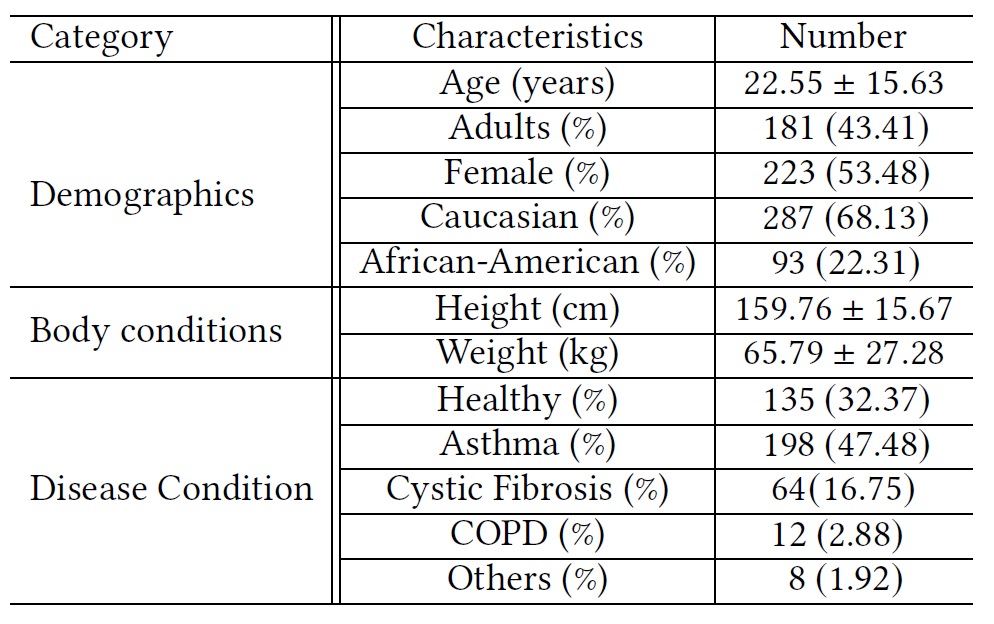 |
| September 2023: Two preprints of our recent works on on-device AI have been made publicly available on arXiv. The first work, Towards Green AI in Fine-Tuning Large Language Models via Adaptive Backpropagation, extends our prior work of ElasticTrainer (published at ACM MobiSys 2023) to Large Language Models (LLMs) and facilitates computationally efficient LLM fine-tuning towards green AI. It can reduce the fine-tuning FLOPs by extra 30% compared to existing techniques such as LoRA, without noticeable accuracy loss. With the same amount of FLOPs reduction, it can provide 4% model accuracy improvement compared to LoRA. The second work, Tackling the Unlimited Staleness in Federated Learning with Intertwined Data and Device Heterogeneities, targets a FL problem motivated by practical system settings, where data samples in certain classes or with particular features may only be produced from some slow clients. Our work leverages gradient inversion to move the staleness of model updates from these slow clients, and can improve the trained model accuracy by 20% and speed up the training progress by 35%, compared to existing techniques in asynchronous FL. The source codes have been publicly available at the Pitt ISL webpage. | |
| April 2023: Our paper, ElasticTrainer: Speeding Up On-Device Training with Runtime Elastic Tensor Selection, has been accepted for publication at the 2023 ACM Conference on Mobile Systems, Applications, and Services (MobiSys). This paper presents the first on-device AI technique that achieves full elasticity of on-device training on resource-constrained mobile and embedded devices. By leveraging the principle of eXplainable AI (XAI) and evaluating the importance of different tensors in training, we allow fully flexible adaptation of the trainable neural network portion at runtime, according to the current training needs and online data patterns, to minimize the training cost without accuracy loss. Check our paper and source codes for more details. | |
| April 2023: Our paper, PTEase: Objective Airway Examination for Pulmonary Telemedicine using Commodity Smartphones, has been accepted for publication at the 2023 ACM Conference on Mobile Systems, Applications, and Services (MobiSys). This is the first mobile health system that turns a commodity smartphone into a fully functional pulmonary examination device to measure the internal physiological conditions of human airways, such as airway caliber, obstruction and possible inflammation. Information about these airway conditions could provide vital clues for precise and objective pulmonary disease evaluation. Check our paper for more details. | |
| Oct 2022: Our paper, AiFi: AI-Enabled WiFi Interference Cancellation with Commodity PHY-Layer Information, has been accepted for publication at the 2022 ACM Conference on Embedded Networked Sensor Systems (SenSys). This is the first work that applies on-device AI techniques to interference cancellation in WiFi networks and enables generalizable interference cancellation on commodity WiFi devices without any extra RF hardware. By using neural network models to mimic WiFi network's PHY-layer operation, AiFi can be generally applied to different types of interference signals ranging from concurrent WiFi transmissions, ZigBee/Bluetooth to wireless baby monitors or even microwave oven, and improves the MAC-layer frame reception rate by 18x. Check our paper for more details. | 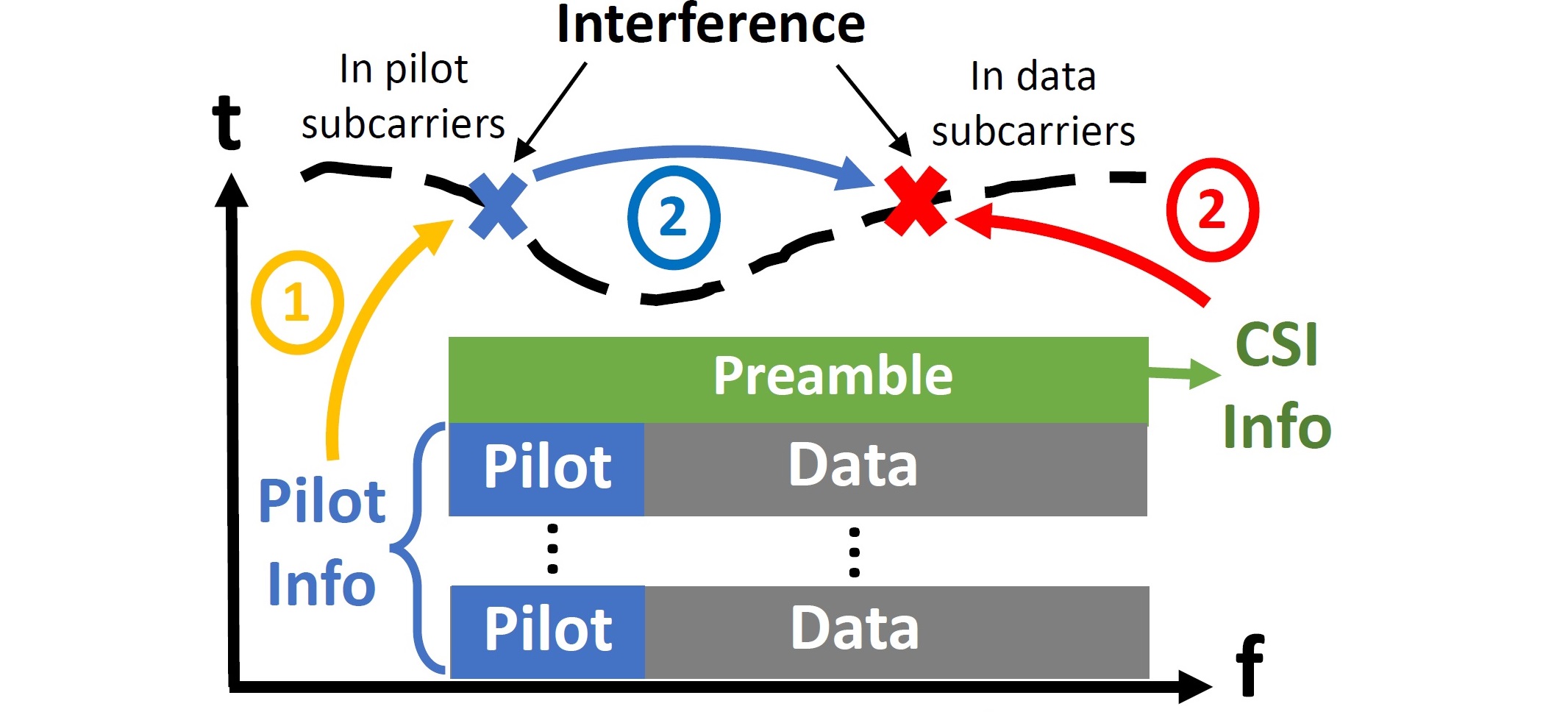 |
| Aug 2022: Our paper, Real-time Neural Network Inference on Extremely Weak Devices: Agile Offloading with Explainable AI, has been accepted for publication at the 2022 ACM Int'l Conference on Mobile Computing and Networking (MobiCom). This is the first work that achieves real-time inference (<20ms) of mainstream neural network models (e.g., ImageNet) on extremely weak MCUs (e.g., STM32 series with <1MB of memory), without impairing the inference accuracy. The usage of eXplainable AI (XAI) techniques allows >6x improvement of feature compressibility during offloading and >8x reduction of the local device's resource consumption. Check our paper and source codes for more details. | |
| May 2022: Our paper, TransFi: Emulating Custom Wireless Physical Layer from Commodity WiFi, has been accepted for publication at the 2022 ACM Int'l Conference on Mobile Systems, Applications and Services (MobiSys). This is the first work that realizes fine-grained signal emulation and allows commodity WiFi devices to emulate custom wireless physical layer, including but not limited to, custom PHY-layer preambles and new ways of agile spectrum usage. It could also improve the performance of cross-technology communication and many other wireless applications by up to 50x, enabling high-speed data communication on par with commodity WiFi! Watch the teaser video for details. | |
| January 2022: Our paper, RAScatter: Achieving Energy-Efficient Backscatter Readers via AI-Assisted Power Adaptation, has been accepted for publication at the 2022 ACM/IEEE Conference on Internet of Things Design and Implementation (IoTDI). | |
| January 2022: Our paper, FaceListener: Recognizing Human Facial Expressions via Acoustic Sensing on Commodity Smartphones, has been accepted for publication at the 2022 ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN). | |
November 2021: Our paper, Eavesdropping User Credentials via GPU Side Channels on Smartphones, has been accepted for publication at the 2022 ACM Int'l Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). This is one of the few works that demonstrate critical security vulnerabilities of mainstream GPUs (QualComm Adreno GPU on Snapdragon SoCs) on smartphones, which allow an unprivileged attacker to eavesdrop the user's sensitive credentials such as app username and password. This attack has been acknowledged by Google and has been incorporated by Google in its future Android security updates. Watch our demo video below for details. |
|
August 2020: Our paper, SpiroSonic: Monitoring Human Lung Function via Acoustic Sensing on Commodity Smartphones, has been accepted for publication at the 2020 International Conference on Mobile Computing and Networking (MobiCom). This is the first work that allows commodity smartphones to be used as a portable spirometer and provide accuracy lung function test results on par with clinical-grade spirometers. This is a collaborative work with the Children's Hospital of Pittsburgh, and could also potentially contribute to in-home evaluation of COVID-19 risks by allowing convenient out-of-clinic lung function evaluation. Watch our presentation video for details. |
|
| May 2020: We have been exploiting the power of modern mobile computing technologies to fight against COVID-19. Our new project of using commodity smartphones for early-stage COVID-19 diagnosis has been funded by NSF, and was reported by several news media internationally. [WGN TV, Daily Mail, News Medical, Medical Express, Pittsburgh Post-Gazette] | |