Release 8.0
A58238-01
Library |
Product |
Contents |
Index |
| Oracle8 Parallel Server Concepts & Administration Release 8.0 A58238-01 |
|
![]()
![]()
This chapter introduces parallel processing and parallel database technologies, which offer great advantages for online transaction processing and decision support applications. The administrator's challenge is to selectively deploy this technology to fully use its multiprocessing power.
To do this successfully you must understand how multiprocessing works, what resources it requires, and when you can-and cannot-effectively apply it. This chapter answers the following questions:
This section defines parallel processing and describes its use.
Parallel processing divides a large task into many smaller tasks, and executes the smaller tasks concurrently on several nodes. As a result, the larger task completes more quickly.
Note: A node is a separate processor, often on a separate machine. Multiple processors, however, can reside on a single machine.
Some tasks can be effectively divided, and thus are good candidates for parallel processing. Other tasks, however, do not lend themselves to this approach.
For example, in a bank with only one teller, all customers must form a single queue to be served. With two tellers, the task can be effectively split so that customers form two queues and are served twice as fast-or they can form a single queue to provide fairness. This is an instance in which parallel processing is an effective solution.
By contrast, if the bank manager must approve all loan requests, parallel processing will not necessarily speed up the flow of loans. No matter how many tellers are available to process loans, all the requests must form a single queue for bank manager approval. No amount of parallel processing can overcome this built-in bottleneck to the system.
Figure 1-1 and Figure 1-2 contrast sequential processing of a single parallel query with parallel processing of the same query.

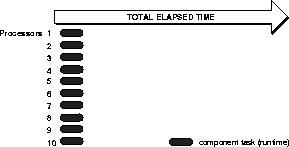
In sequential processing, the query is executed as a single large task. In parallel processing, the query is divided into multiple smaller tasks, and each component task is executed on a separate node.
Figure 1-3 and Figure 1-4 contrast sequential processing with parallel processing of multiple independent tasks from an online transaction processing (OLTP) environment.
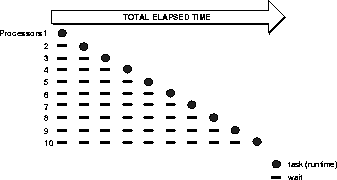

In sequential processing, independent tasks compete for a single resource. Only task 1 runs without having to wait. Task 2 must wait until task 1 has completed; task 3 must wait until tasks 1 and 2 have completed, and so on. (Although the figure shows the independent tasks as the same size, the size of the tasks will vary.) By contrast, in parallel processing (for example, a parallel server on a symmetric multiprocessor), more CPU power is assigned to the tasks. Each independent task executes immediately on its own processor: no wait time is involved.
Effective implementation of parallel processing involves two challenges:
A parallel processing system has the following characteristics:
Parallel processing architectures may support:
Clustered and MPP machines have multiple memories, with each CPU typically having its own memory. Such systems promise significant price/performance benefits by using commodity memory and bus components to eliminate memory bottlenecks.
Database management systems that support only one type of hardware limit the portability of applications, the potential to migrate applications to new hardware systems, and the scalability of applications. Oracle Parallel Server (OPS) exploits both clusters and MPP systems, and has no such limitations. Oracle without the Parallel Server Option exploits single CPU or SMP machines.
Parallel database software must effectively deploy the system's processing power to handle diverse applications: online transaction processing (OLTP) applications, decision support system (DSS) applications, as well as a mixed OLTP and DSS workload. OLTP applications are characterized by short transactions which have low CPU and I/O usage. DSS applications are characterized by long transactions, with high CPU and I/O usage.
Parallel database software is often specialized-usually to serve as query processors. Since they are designed to serve a single function, however, specialized servers do not provide a common foundation for integrated operations. These include online decision support, batch reporting, data warehousing, OLTP, distributed operations, and high availability systems. Specialized servers have been used most successfully in the area of very large databases: in DSS applications, for example.
Versatile parallel database software should offer excellent price/performance on open systems hardware, and be designed to serve a wide variety of enterprise computing needs. Features such as online backup, data replication, portability, interoperability, and support for a wide variety of client tools can enable a parallel server to support application integration, distributed operations, and mixed application workloads.
A variety of hardware architectures allow multiple computers to share access to data, software, or peripheral devices. A parallel database is designed to take advantage of such architectures by running multiple instances which "share" a single physical database. In appropriate applications, a parallel server can allow access to a single database by users on multiple machines, with increased performance.
A parallel server processes transactions in parallel by servicing a stream of transactions using multiple CPUs on different nodes, where each CPU processes an entire transaction. Using parallel data manipulation language you can have one transaction being performed by multiple nodes. This is an efficient approach because many applications consist of online insert and update transactions which tend to have short data access requirements. In addition to balancing the workload among CPUs, the parallel database provides for concurrent access to data and protects data integrity.
See Also: "Is Parallel Server the Oracle Configuration You Need?" on page 1-17 for a discussion of the available Oracle configurations.
This section describes key elements of parallel processing:
You can measure the performance goals of parallel processing in terms of two important properties:
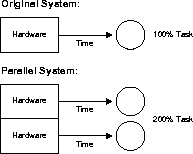
Speedup is the extent to which more hardware can perform the same task in less time than the original system. With added hardware, speedup holds the task constant and measures time savings. Figure 1-5 shows how each parallel hardware system performs half of the original task in half the time required to perform it on a single system.
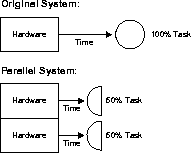
With good speedup, additional processors reduce system response time. You can measure speedup using this formula: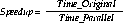
where
|
Time_Parallel |
is the elapsed time spent by a larger, parallel system on the given task |
For example, if the original system took 60 seconds to perform a task, and two parallel systems took 30 seconds, then the value of speedup would equal 2. 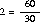
A value of n, where n times more hardware is used indicates the ideal of linear speedup: when twice as much hardware can perform the same task in half the time (or when three times as much hardware performs the same task in a third of the time, and so on).
Attention: For most OLTP applications, no speedup can be expected: only scaleup. The overhead due to synchronization may, in fact, cause speed-down.
Scaleup is the factor m that expresses how much more work can be done in the same time period by a system n times larger. With added hardware, a formula for scaleup holds the time constant, and measures the increased size of the job which can be done.
With good scaleup, if transaction volumes grow, you can keep response time constant by adding hardware resources such as CPUs.
You can measure scaleup using this formula: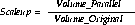
where
|
Volume_Parallel |
is the transaction volume processed in a given amount of time on a parallel system |
For example, if the original system can process 100 transactions in a given amount of time, and the parallel system can process 200 transactions in this amount of time, then the value of scaleup would be equal to 2. That is, 200/100 = 2. A value of 2 indicates the ideal of linear scaleup: when twice as much hardware can process twice the data volume in the same amount of time.
Coordination of concurrent tasks is called synchronization. Synchronization is necessary for correctness. The key to successful parallel processing is to divide up tasks so that very little synchronization is necessary. The less synchronization necessary, the better the speedup and scaleup.
In parallel processing between nodes, a high-speed interconnect is required among the parallel processors. The overhead of this synchronization can be very expensive if a great deal of inter-node communication is necessary. For parallel processing within a node, messaging is not necessary: shared memory is used instead. Messaging and locking between nodes is handled by the Integrated Distributed Lock Manager (IDLM).
The amount of synchronization depends on the amount of resources and the number of users and tasks working on the resources. Little synchronization may be needed to coordinate a small number of concurrent tasks, but lots of synchronization may be necessary to coordinate many concurrent tasks.
A great deal of time spent in synchronization indicates high contention for resources.
Attention: Too much time spent in synchronization can diminish the benefits of parallel processing. With less time spent in synchronization, better speedup and scaleup can be achieved.
Response time equals time spent waiting and time spent doing useful work. Table 1-1 illustrates how overhead increases as more concurrent processes are added. If 3 processes request a service at the same time, and they are served serially, then response time for process 1 is 1 second. Response time for process 2 is 2 seconds (waiting 1 second for process 1 to complete, then being serviced for 1 second). Response time for process 3 is 3 seconds (2 seconds waiting time plus 1 second service time).
| Process Number | Service Time | Waiting Time | Response Time |
|---|---|---|---|
|
1 |
1 second |
0 seconds |
1 second |
|
2 |
1 second |
1 second |
2 seconds |
|
3 |
1 second |
2 seconds |
3 seconds |
One task, in fact, may require multiple messages. If tasks must continually wait to synchronize, then several messages may be needed per task.
While synchronization is a necessary element of parallel processing to preserve correctness, you need to manage its cost in terms of performance and system resources. Different kinds of parallel processing software may permit synchronization to be achieved, but a given approach may or may not be cost-effective.
Sometimes synchronization can be accomplished very cheaply. In other cases, however, the cost of synchronization may be too high. For example, if one table takes inserts from many nodes, a lot of synchronization is necessary. There will be high contention from the different nodes to insert into the same datablock: the datablock must be passed between the different nodes. This kind of synchronization can be done--but not efficiently.
See Also: Chapter 12, "Application Analysis"
Chapter 19, "Tuning the System to Optimize Performance"
Chapter 8, "Integrated Distributed Lock Manager: Access to Resources"
Locks are fundamentally a way of synchronizing tasks. Many different locking mechanisms are necessary to enable the synchronization of tasks required by parallel processing.
The Integrated Distributed Lock Manager (Integrated DLM, or IDLM) is the internal locking facility used with Oracle Parallel Server. It coordinates resource sharing between nodes running a parallel server. The instances of a parallel server use the Integrated Distributed Lock Manager to communicate with each other and coordinate modification of database resources. Each node operates independently of other nodes, except when contending for the same resource.
Note: In Oracle8 the Integrated Distributed Lock Manager facility replaces the external Distributed Lock Manager (DLM) which was used in previous releases. This enhancement frees Oracle performance from the limitations of external lock managers.
The IDLM allows applications to synchronize access to resources such as data, software, and peripheral devices, so that concurrent requests for the same resource are coordinated between applications running on different nodes.
The IDLM performs the following services for applications:
See Also: Chapter 7, "Overview of Locking Mechanisms", for a discussion of locking mechanisms internal to the Oracle database.
Chapter 8, "Integrated Distributed Lock Manager: Access to Resources"
Parallel processing requires fast and efficient communication between nodes: a system with high bandwidth and low latency which efficiently communicates with the IDLM.
Bandwidth is the total size of messages which can be sent per second. Latency is the time (in seconds) it takes to place a message on the interconnect. Latency thus indicates the number of messages which can be put on the interconnect per second. An interconnect with high bandwidth is like a wide highway with many lanes to accommodate heavy traffic: the number of lanes affects the speed at which traffic can move. An interconnect with low latency is like a highway with an entrance ramp which permits vehicles to enter without delay: the cost of getting on the highway is low.
Most MPP systems and clusters are being designed with networks that have reasonably high bandwidth. Latency, on the other hand, is an operating system issue predominantly having to do with software. MPP systems and most clusters characteristically use interconnects with high bandwidth and low latency; other clusters may use Ethernet connections with relatively low bandwidth and high latency.
Parallel processing can benefit certain kinds of applications by providing:
Improved response time can be achieved either by breaking up a large task into smaller components or by reducing wait time, as was shown in Figure 1-3.
Table 1-2 shows which types of workload can attain speedup and scaleup with properly implemented parallel processing.
| Workload | Speedup | Scaleup |
|
OLTP |
No |
Yes |
|
DSS |
Yes |
Yes |
|
Batch (Mixed) |
Possible |
Yes |
|
Parallel Query |
Yes |
Yes |
If tasks can run independently of one another, they can be distributed to different CPUs or nodes and there will be a scaleup: more processes will be able to run through the database in the same amount of time.
If processes can run ten times faster, then the system can accomplish ten times more in the original amount of time. The parallel query feature, for example, permits scaleup: a system might maintain the same response time if the data queried increases tenfold, or if more users can be served. Oracle Parallel Server without the parallel query feature also permits scaleup, but by running the same query sequentially on different nodes.
With a mixed workload of DSS, OLTP, and reporting applications, scaleup can be achieved by running multiple programs on different nodes. Speedup can also be achieved if you rewrite the batch programs, splitting them into a number of parallel streams to take advantage of the multiple CPUs which are now available.
DSS applications and parallel query can attain speedup with parallel processing: each transaction can run faster.
For OLTP applications, however, no speedup can be expected: only scaleup. With OLTP applications each process is independent: even with parallel processing, each insert or update on an order table will still run at the same speed. In fact, the overhead due to synchronization may cause a slight speed-down. Since each of the operations being done is small, it is inappropriate to attempt to parallelize them; the overhead would be greater than the benefit.
Speedup can also be achieved with batch processing, but the degree of speedup depends on the synchronization between tasks.
Parallel database technology can benefit certain kinds of applications by enabling:
With more CPUs available to an application, higher speedup and scaleup can be attained. The improvement in performance depends on the degree of inter-node locking and synchronization activities. Each lock operation is processor and message intensive; there can be a lot of latency. The volume of lock operations and database contention, as well as the throughput and performance of the IDLM, ultimately determine the scalability of the system.
Nodes are isolated from each other, so a failure at one node does not bring the whole system down. The remaining nodes can recover the failed node and continue to provide data access to users. This means that data is much more available than it would be with a single node upon node failure, and amounts to significantly higher availability of the database.
An Oracle Parallel Server environment is extremely flexible. Instances can be allocated or deallocated as necessary. When there is high demand for the database, more instances can be temporarily allocated. The instances can be deallocated and used for other purposes once they are no longer necessary.
Parallel database technology can make it possible to overcome memory limits, enabling a single system to serve thousands of users.
This section describes the following Oracle configurations, which can deliver high performance for different types of applications:
The parallel server is one of several Oracle options which provide a high-performance relational database serving many users. These configurations can be combined to suit your needs. A parallel server can be one of several servers in a distributed database environment, and the client-server configuration can combine various Oracle configurations into a hybrid system to meet specific application requirements.
Note: Support for any given Oracle configuration is platform-dependent; check to confirm that your platform supports the configuration you want.
For optimal performance, configure your system according to your particular application requirements and available resources, then design and tune the database and applications to make the best use of the configuration. Consider also the migration of existing hardware or software to the new system or to future systems.
The following sections help you determine which Oracle configuration best meets your needs.
See Also: Chapter 3, "Parallel Hardware Architecture"
Figure 1-7 illustrates a single instance database system running on a symmetric multiprocessor (SMP). The database itself is located on a set of disks.
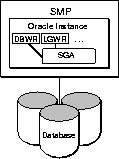
A single instance accessing a single database can improve performance by running on a larger computer. A large single computer does not require coordination between several nodes and generally performs better than two small computers in a multinode system. However, two small computers often cost less than one large one.
The cost of redesigning and tuning your database and applications for the Parallel Server Option might be significant if you want to migrate from a single computer to a multinode system. In situations like this, consider whether, a larger single computer might be a better solution than moving to a parallel server.
See Also: Oracle8 Concepts for complete information about single instance Oracle.
Oracle with the Parallel Server Option running on a cluster or MPP is called a multi-instance database system, illustrated in Figure 1-8. This is an excellent solution for applications which can be configured to minimize the passing of data between instances on different nodes.
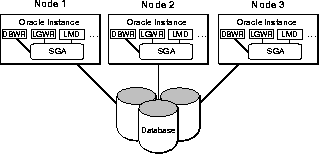
Note that this database system requires the LMD process on each instance. These processes communicate with each other to coordinate global locking.
In a parallel server, instances are decoupled from databases. In exclusive mode, there is a one-to-one correspondence of instance to database. In shared (parallel) mode, however, there can be many instances to a single database.
In general, any single application performs best when it has exclusive access to a database on a larger system, as compared with its performance on a smaller node of a multinode environment. This is because the cost of synchronization may become too high if you go to a multinode environment. The performance difference depends on characteristics of that application and all other applications sharing access to the database.
Applications with one or both of the following characteristics are well suited to run on separate instances of a parallel server:
See Also: "Enabling and Disabling Parallel Server" on page 4-2
Chapter 8, "Integrated Distributed Lock Manager: Access to Resources"
Oracle8 Concepts for more information on the DBWR, LGWR, and LMD background processes.
Several Oracle servers and databases can be linked to form a distributed database system. This configuration includes multiple databases, each of which is accessed directly by a single server and can be accessed indirectly by other instances through server-to-server cooperation. Each node can be used for database processing, but the data is permanently partitioned among the nodes. A parallel server, in contrast, has multiple instances which share direct access to one database.
Note: Oracle Parallel Server can be one of the constituents of a distributed database.
Figure 1-9 illustrates a distributed database system. This database system requires the RECO background process on each instance. There is no LCK, LMON, or LMD background process because this is not an Oracle Parallel Server configuration, and the Integrated Distributed Lock Manager is not needed.
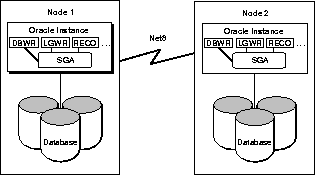
The multiple databases of a distributed system can be treated as one logical database, because servers can access remote databases transparently, using Net8.
If your data can be partitioned into multiple databases with minimal overlap, you can use a distributed database system instead of a parallel server, sharing data between the databases with Net8. A parallel server provides automatic data sharing among nodes through the common database.
A distributed database system allows you to keep your data at several widely separated sites. Users can access data from databases which are geographically distant, as long as network connections exist between the separate nodes. A parallel server requires all data to be at a single site because of the requirement for low latency, high bandwidth communication between nodes, but it can also be part of a distributed database system. Such a system is illustrated in Figure 1-10.
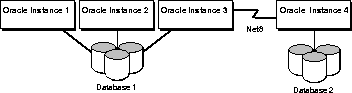
Multiple databases require separate database administration, and a distributed database system requires coordinated administration of the databases and network protocols. A parallel server can consolidate several databases to simplify administrative tasks.
Multiple databases can provide greater availability than a single instance accessing a single database, because an instance failure in a distributed database system does not prevent access to data in the other databases: only the database owned by the failed instance is inaccessible. A parallel server, however, allows continued access to all data when one instance fails, including data which was accessed by the instance running on the failed node.
A parallel server accessing a single consolidated database can avoid the need for distributed updates, inserts, or deletions and more expensive two-phase commits by allowing a transaction on any node to write to multiple tables simultaneously, regardless of which nodes usually write to those tables.
See Also: Oracle8 Distributed Database Systems for complete information about Oracle distributed database features.
Any of the Oracle configurations can run in a client-server environment. In Oracle, a client application runs on a remote computer, using Net8 to access an Oracle server through a network. The performance of this configuration is typically limited to the power of the single server node.
Figure 1-11 illustrates an Oracle client-server system.
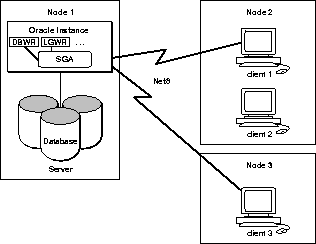
Note: Client-server processing is suitable for any Oracle configuration. Check your Oracle platform-specific documentation to see whether it is implemented on your platform.
The client-server configuration allows you to off-load processing from the computer which runs an Oracle server. If you have too many applications running on one machine, you can off-load them to improve performance. However, if your database server is reaching its processing limits you might want to move either to a larger machine or to a multinode system.
For compute-intensive applications, you could run some applications on one node of a multinode system while running Oracle and other applications on another node, or on several other nodes. In this way you could effectively use various nodes of a parallel machine as client nodes, and one as a server node.
If the database consists of several distinct high-throughput parts, a parallel server running on high-performance nodes can provide quick processing for each part of the database while also handling occasional access across parts.
Remember that a client-server configuration requires that all communications between the client application and the database take place over the network. This may not be appropriate where a very high volume of such communications is required--as in many batch applications.
See Also: "Client-Server Architecture" in Oracle8 Concepts
With its parallel execution features, Oracle can divide the work of processing certain types of SQL statements among multiple query server processes.
Oracle Parallel Server provides the framework for parallel execution to work between nodes. Parallel execution features behave the same way in Oracle with or without the Parallel Server Option. The only difference is that OPS enables multiple nodes to execute on behalf of a single query or other parallel operation.
In some applications (notably data warehousing applications), an individual query consumes a great deal of CPU resource and disk I/O, unlike most online insert or update transactions. To take advantage of multiprocessing systems, the data server must parallelize individual queries into units of work which can be processed simultaneously. Figure 1-12 shows an example of parallel query processing.
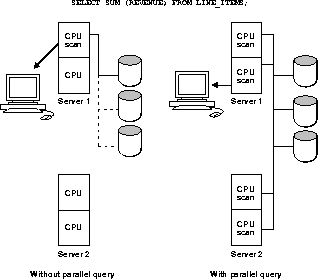
If the query were not processed in parallel, disks would be read serially with a single I/O. A single CPU would have to scan all rows in the LINE_ITEMS table and total the revenues across all rows. With the query parallelized, disks are read in parallel, with multiple I/Os. Several CPUs can each scan a part of the table in parallel, and aggregate the results. Parallel query benefits not only from multiple CPUs but also from more of the available I/O bandwidth.
See Also: Oracle8 Concepts and Oracle8 Tuning for a detailed treatment of parallel execution.