Release 8.0
A58238-01
Library |
Product |
Contents |
Index |
| Oracle8 Parallel Server Concepts & Administration Release 8.0 A58238-01 |
|
![]()
![]()
This chapter describes Oracle recovery features on a parallel server. It covers the following topics:
This chapter discusses client-side application failover, and three types of recovery:
This section covers the following topics:
Note: To use application failover, you must have the Oracle8 Enterprise Edition and the Parallel Server Option. For more information, please refer to Getting to Know Oracle8 and the Oracle8 Enterprise Edition.
On Oracle Parallel Server, application failover is the ability of the application to automatically reconnect if the connection to the database is broken. Any active transaction will be rolled back, but the new database connection will otherwise be identical to the original one. This is true only if the connection was lost because the instance died due to ALTER SYSTEM DISCONNECT SESSION.
Often a client really wants to connect to an application rather than to a database instance. With application failover the client sees no loss of connection while there is a surviving instance serving the application, and is normally able to continue SELECTs started before the instance failed. The DBA can control which applications run on various instances, and create a failover order for each application.
Note that after failover, only select or fetch calls are replayed; all other calls will receive an error message. Also, if the client's process dies but the instance does not, then failover will not occur.
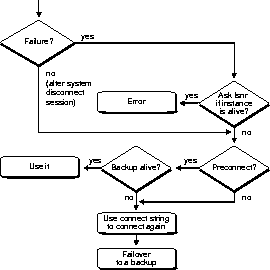
The DBA can configure the connect string for the application at the names server, or put it in the TNSNAMES.ORA file. Alternatively, the connect string can be hard coded in the application. For each application, the names server provides information about the listener, the instance group, and the failover mode. The connect string failover_mode field specifies the type and method of failover. For more information on syntax, please refer to the Net8 Administrator's Guide.
The client's failover functionality is determined by the "TYPE" keyword in the connect string. The choices are:
Improving the speed of application failover often requires putting more work on the backup instance. The DBA can use the METHOD keyword in the connect string to configure the BASIC or PRECONNECT performance options.
For application failover to work correctly, the connect string used to attach initially must also go to a valid instance at failover time. This means that the listener to which the client connects at failover time must be able to either establish a connection with the right instance, or refuse the connection so that the client can chose another listener (via a description_list or an address_list in the connect string).
There are several ways of achieving this. The approach to use depends on the exact situation, and the role that the listeners play in connecting. The solutions are described in this section.
Failover with the Multi-threaded Server. To use application failover with the multi-threaded server, you must set the MTS_SERVICE parameter to the same value for every instance. This value must match the value of the SID in the connect string. If there is more than one listener for the database, then the dispatchers must be configured individually with the (LISTENERS=) clause of the MTS_DISPATCHER parameter.
Also note that the techniques described for dedicated servers will also work for multi-threaded servers as long as the mts_service is the same as the instance SID.
Several dynamic performance views are available to help you tune the MTS dispatcher:
These views contain statistics which show message rates and buffer rates. Using these views you can adjust the relationship between the number of events in a loop and how busy the dispatcher is, so as to minimize overhead. Note that the Net8 parameter SDUSIZE determines how large a message you can send at one time.
See Also: Oracle8 Reference for details on views and statistics.
Failover with the Connection Load Balancer. The Net8 generic listener can support plug-in load balancing. (This is not required for single instance failover.) On some platforms the Oracle Connect Load Balancing (CLB) module can perform this function. The CLB allows the SID portion of the connect string to be an instance group.
An example of an explicit connect string is:
(DESCRIPTION= (ADDRESS=(PROTOCOL=tcp)(HOST=westreg)(port=1512)) (CONNECT_DATA=(SID=OE)(SERVER=SHARED) (FAILOVER_MODE=(TYPE=SELECT)(METHOD=BASIC))))
The first line announces that this is a connect string. The second line provides the listener's address. The third line begins with the instance group definition. This is the set of instances on which this application is served. The third line concludes by specifying a connection via MTS. The remaining line provides the new data about the failover mode. The TYPE field specifies the functionality option, and the METHOD field specifies the method.
Note that you can specify an instance group in the connect string.
Failover with Dedicated Servers. To accomplish failover with dedicated servers, there must be multiple listeners (unless all the instances are on the same machine). This will usually mean that the connect string will contain either a description list or an address list. For failover to work properly, the listeners must know whether or not the instance is alive. This is accomplished by having the instances register themselves with their listeners, and the LISTENER.ORA file not contain the instance's SID. The instance registration is configured via the LOCAL_LISTENERS parameter (see documentation on this parameter). By using this technique, an address list may be employed to achieve a "primary/backup" relationship between two (or more) instances. If the first instance is not up the connection to the first listener in the address_list will fail and the client will proceed to try the second. Likewise, a description_list will provide the semantics that connections are spread evenly over the living instances. See the documentation on address_lists and description_lists for more details.
Preconnect Connect Strings. When using preconnect, the client must make a connection to a backup while the primary instance is still up. The DBA should provide a connect string to use as a backup. In this way, the DBA can be sure that the backup instance will be different from the primary instance. This backup connect string is provided with the BACKUP keyword in the FAILOVER_MODE portion of the connect string. This can be either an explicit address or an alias to look up. If no backup is provided, failover will use the original connect string. This will work, but some percent of clients will get the same backup as primary, and will have to reconnect at failover time.
In the following example, one instance is running on each node. The database is called i1 and the ORACLE_SIDs are i11 and i12. There is one listener on each node listening for the local instance and the instance groups are as follows:
group g1=(i11) group g2=(i12) group gc=(i11,i12)
In the TNSNAMES.ORA file you would enter:
i11 = (DESCRIPTION= (ADDRESS=(PROTOCOL=TCP)(HOST=host1)(PORT=1521)) (CONNECT_DATA=(SID=i11)(SERVER=DEDICATED) (FAILOVER_MODE=(TYPE=select)(METHOD=preconnect) (BACKUP=i12)) ) ) i12 = (DESCRIPTION= (ADDRESS=(PROTOCOL=TCP)(HOST=host2)(PORT=1521)) (CONNECT_DATA=(SID=i12)(SERVER=DEDICATED) (FAILOVER_MODE=(TYPE=select)(METHOD=preconnect) (BACKUP=i11)) ) )
This way, each client uses either connect string i11 or i12, and establishes a backup connection using the other connect string. So if a client uses connect string i11, it will initially connect to instance 1, and use instance 2 if instance 1 fails.
The view V$SESSION has the following fields related to failover:
|
FAILED_OVER |
TRUE if using the backup, otherwise FALSE |
|
TYPE |
One of SELECT, SESSION, or NONE |
|
METHOD |
Either BASIC or PRECONNECT |
This section explains how the DBA can bring down an instance or a session. For complete syntax of available SQL statements, see the Oracle8 Server SQL Reference.
The TRANSACTIONAL option to the SHUTDOWN command enables the DBA to do a planned shutdown of one instance while minimally interrupting clients. This option will wait for ongoing transactions to complete, and is useful for installing patch releases, or other times when the instance must be brought down without interrupting service.
While waiting, no client can start a new transaction on the instance. Clients will be disconnected if they try to start a transaction, and this will trigger failover, if it is enabled. When the last transaction completes the primary instance performs a SHUTDOWN IMMEDIATE. If failover is enabled, SHUTDOWN TRANSACTIONAL normally prevents any clients from losing work, while not requiring all users to log off first, as a SHUTDOWN NORMAL would. Clients are automatically reconnected to the instance.
The ALTER SYSTEM DISCONNECT SESSION POST_TRANSACTION statement disconnects a session on the first call after its current transaction has been finished. The application will failover automatically.
ALTER SYSTEM DISCONNECT SESSION `sid,serial#' POST_TRANSACTION
where
|
sid |
is the system identifier |
|
serial# |
is the session serial number, from the V$SESSION view |
The POST_TRANSACTION option works well with failover as a way for the DBA to control load. If one instance is overloaded, the DBA can manually disconnect a group of sessions using this option. Since the option guarantees that there is no transaction at the time the session is disconnected, the user should never notice the shift, except for a slight delay executing the next command following the disconnect.
This section describes multiple user handles and callbacks.
Failover is supported for multiple user handles. In OCI the server context handle and the user handle are decoupled. You can have multiple user handles related to the server context handle, and multiple users can thus share the same connection to the database.
If the connection is destroyed, then every user associated with that connection will be failed over. But if a single user process is destroyed then failover does not occur because the connection is still there. Failover will not reauthenticate migrateable user handles.
See Also: Programmer's Guide to the Oracle Call Interface, Volume I: OCI Concepts, and Programmer's Guide to the Oracle Call Interface, Volume II: OCI Reference
Frequently failure of one instance and failover to another takes some time. Because of this delay, you may want to inform the user that failover is in progress, and request that the user stand by. Additionally, the session on the initial instance may have received some ALTER SESSION commands. These will not be automatically replayed on the second instance. You may want to ensure that these commands will be replayed on the second instance.
To address these problems, you can register a callback function. Failover will call the callback function several times during the course of reestablishing the user's session. The first call occurs when instance connection loss is first detected, so the application can inform the user of upcoming delay. If failover is successful, the second call occurs when the connection is reestablished and usable. At this time the client may wish to replay ALTER SESSION statements and inform the user that failover has occurred. If failover is unsuccessful, then the callback will be called to inform the application that failover will not take place. Additionally, the callback will be called each time a user handle besides the primary handle is reauthenticated on the new connection.
See Also: Oracle Call Interface Programmer's Guide
The elapsed time of failover includes instance recovery as well as time needed to reconnect to the database. For best performance of failover, therefore, you should tune instance recovery by having frequent checkpoints, and so on.
Performance can also be improved by having multiple listeners, using the multi-threaded server or dedicated servers. Note in particular that MTS connections tend to be much faster than connections via dedicated servers.
The number of users trying to failover at the same time also affects failover performance. Failover occurs when users attempt to perform actions. In some applications, many users may be logged in, but few may be performing work at any given time. In such as case, if no instance recovery is necessary and only a few users are failing over at any given time, failover may be very fast. Thus the amount of effort you may decide to put in to tuning failover performance will probably be related to the number of concurrent users you expect. In a three-tier application design, for example, it might be best to have few connections; for faster failover each connection could have several sessions associated with it.
When a connection is lost, you will see the following effects:
See Also: Oracle Call Interface Programmer's Guide
The following sections describe the recovery performed after failure of instances accessing the database in shared mode.
After instance failure, Oracle uses the online redo log files to perform automatic recovery of the database. For a single instance running in exclusive mode, instance recovery occurs as soon as the instance starts up again after it has failed or shut down abnormally.
When instances accessing the database in shared mode fail, online instance recovery is performed automatically. Instances that continue running on other nodes are not affected, as long as they are reading from the buffer cache. If instances attempt to write, the transaction will stop. All operations to the database are suspended until cache recovery of the failed instance is complete.
See Also: Oracle8 Backup and Recovery Guide.
A parallel server performs instance recovery by coordinating recovery operations through the SMON processes of the other running instances. If one instance fails, the SMON process of another instance notices the failure and automatically performs instance recovery for the failed instance.
Instance recovery does not include restarting the failed instance or any applications that were running on that instance. Applications that were running may continue by failover, as described in "Client-side Application Failover" on page 22-2.
When one instance performs recovery for another instance that has failed, the surviving instance reads the redo log entries generated by the failed instance, and uses that information to ensure that all committed transactions are reflected in the database. No data from committed transactions is lost. The instance that is performing recovery rolls back any transactions that were active at the time of the failure and releases any resources being used by those transactions.
As long as one instance continues running, its SMON process performs instance recovery for any other instances that fail in a parallel server.
If all instances of a parallel server fail, instance recovery is performed automatically the next time an instance opens the database. The instance does not have to be one of the instances that failed, and it can mount the database in either shared or exclusive mode from any node of the parallel server. This recovery procedure is the same for Oracle running in shared mode as it is for Oracle in exclusive mode, except that one instance performs instance recovery for all of the instances that failed.
Incremental checkpointing improves the performance of crash and instance recovery (but not media recovery). An incremental checkpoint records the position in the redo thread (log) from which crash/instance recovery needs to begin. This log position is determined by the oldest dirty buffer in the buffer cache. The incremental checkpoint information is maintained periodically with minimal or no overhead during normal processing.
Recovery performance is roughly proportional to the number of buffers that had not been written to the database prior to the crash. You can influence the performance of crash or instance recovery by setting the parameter DB_BLOCK_MAX_DIRTY_TARGET, which specifies an upper bound on the number of dirty buffers that can be present in the buffer cache of an instance at any moment in time. Thus, it is possible to influence recovery time for situations where the buffer cache is very large and/or where there are stringent limitations on the duration of crash/instance recovery. Smaller values of this parameter impose higher overhead during normal processing since more buffers have to be written. On the other hand, the smaller the value of this parameter, the better the recovery performance, since fewer blocks need to be recovered.
Incremental checkpoint information is maintained automatically by Oracle8 Server without affecting other checkpoints (such as log switch checkpoints and user-specified checkpoints). In other words, incremental checkpointing occurs independently of other checkpoints occurring in the instance.
Incremental checkpointing is beneficial for recovery in a single instance as well as a multi-instance environment.
An instance that performs recovery for another instance must have access to all of the online datafiles that the failed instance was accessing. When instance recovery fails because a datafile fails verification, the instance that attempted to perform recovery does not fail, but a message is written to the ALERT file.
After you correct the problem that prevented access to the database files, you must use the SQL statement ALTER SYSTEM CHECK DATAFILES to make the files available to the instance.
See Also: "Datafiles" on page 6-2
With a parallel server you can use the dynamic parameter FREEZE_DB_FOR_FAST_INSTANCE_RECOVERY to control freezing of the database during instance recovery. Note that multiple instances must have the same value for this parameter.
When this parameter is set to TRUE, Oracle freezes the whole database during instance recovery. The advantage of freezing the whole database is to stop all other disk activities except those for instance recovery. Instance recovery may thus complete sooner. The drawback of freezing the whole database is that it becomes unavailable during instance recovery.
When this parameter is set to FALSE, Oracle does not freeze the whole database, thus part of the unaffected database will be accessible during instance recovery.
The system attempts to pick a good default value intelligently.
To see the number of times the whole database is frozen for instance recovery after this instance has started up, you can check the "instance recovery database freeze count" statistic in V$SYSSTAT.
See Also: Oracle8 Reference
Figure 22-2 illustrates the degree of database availability during each phase of Oracle instance recovery.
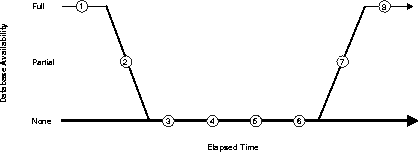
Phases of recovery are these:
During phase 5 (forward application of the redo log), database access is limited by the transitional state of the buffer cache. The following data access restrictions exist for all user data in all datafiles, regardless of whether you are using hashed or fine grain locking, or any particular features:
Reads of buffers already in the cache with the correct global lock can be done, since they do not involve any I/O or lock operations.
The transitional state of the buffer cache begins at the conclusion of the initial lock scan phase when instance recovery is first started by scanning for dead redo threads. Subsequent lock scans are made if new dead threads are discovered. This state lasts while the redo log is applied (cache recovery) and ends when the redo logs have been applied and the file headers have been updated. Cache recovery operations conclude with validation of the invalid locks, which occurs after the buffer cache state is normalized.
After a media failure that results in the loss of one or more database files, you must use backups of the datafiles to recover the database.
If you are using Recovery Manager, you might also need to apply incremental backups, archived redo log files and a backup of the control file.
If you are using operating system utilities, you might need to apply archived redo log files to the database and use a backup of the control file.
This section describes:
See Also: Oracle8 Backup and Recovery Guide for procedures to recover from various kinds of media failure.
You can perform complete media recovery in either exclusive or shared mode. The following table shows what the status of the database must be, for you to recover particular database objects.
You can recover multiple datafiles or tablespaces on multiple instances simultaneously.
With operating system utilities you can perform open database recovery of tablespaces or datafiles in shared mode, by using the Server Manager command RECOVER TABLESPACE or RECOVER DATAFILE.
You can use the Server Manager RECOVER DATABASE command to recover a database that is mounted in shared mode, but not open. Only one instance can issue this command in a parallel server.
Note: The recommended method of recovering a database is to use Server Manager. Direct use of the ALTER DATABASE RECOVER SQL command is not recommended.
With Recovery Manager, you can issue the following statements to restore and recover the files:
Incomplete media recovery can be performed while the database is mounted in shared or exclusive mode, but not open by any instance, using the following database recovery options:
With Recovery Manager:
With operating system utilities:
See Also: Oracle8 Backup and Recovery Guide
Media recovery of a database accessed by a parallel server may require multiple archived log files to be open at the same time. Because each instance writes redo log data to a separate thread of redo, recovery may require as many as one archived log file per thread.
However, if a thread's online redo log contains enough recovery information, restoring any archived log files for that thread will be unnecessary.
Recovery Manager automatically restores and applies the archive logs required. By default, Recovery Manager will restore archive logs to the LOG_ARCHIVE_DEST directory of the instances to which it connects. If you are using multiple nodes to restore and recover, this means that the archive logs may be restored to any of the nodes performing the restore/recover. The nodes which will actually read the restored logs and perform the roll forward is the target node to which the connection was initially made. You must ensure that the logs are readable from that node.
See Also: Oracle8 Backup and Recovery Guide for information about overriding the location to which Recovery Manager restores archive logs.
When recovering using Server Manager, you are prompted for the archived log files as they are needed. Messages supply information about the required files, and Server Manager prompts you for the filename.
For example, if the log history is enabled and the filename format is LOG_T%t_SEQ%s, where %t is the thread and %s is the log sequence number, then you might receive these messages to begin recovery with SCN 9523 in thread 8:
ORA-00279: Change 9523 generated at 27/09/91 11:42:54 needed for thread 8 ORA-00289: Suggestion : LOG_T8_SEQ438 ORA-00280: Change 9523 for thread 8 is in sequence 438 Specify log: {<RET> = suggested | filename | AUTO | FROM | CANCEL}
If you use the ALTER DATABASE statement with the RECOVER clause instead of Server Manager, you receive these messages but not the prompt. Redo log files may be required for each enabled thread in the parallel server. Oracle issues a message when a log file is no longer needed. The next log file for that thread is then requested, unless the thread was disabled or recovery is finished.
If recovery reaches a time when an additional thread was enabled, Oracle simply requests the archived log file for that thread. Whenever an instance enables a thread, it writes a redo entry that records the change; therefore, all necessary information about threads is available from the redo log files during recovery.
If recovery reaches a time when a thread was disabled, Oracle informs you that the log file for that thread is no longer needed and does not request any further log files for the thread.
Note: If Oracle reconstructs the names of archived redo log files, the format that LOG_ARCHIVE_FORMAT specifies for the instance doing recovery must be the same as the format specified for the instances that archived the files. All instances should use the same value of LOG_ARCHIVE_FORMAT in a parallel server, and the instance performing recovery should also use that value. You can specify a different value of LOG_ARCHIVE_DEST during recovery if the archived redo log files are not at their original archive destinations.
Disaster recovery is used when a failure makes a whole site unavailable. In this case, you can recover at an alternate site using open or closed database backups. (To recover up to the latest point in time, all logs must be available at a remote site; otherwise some work may be lost.)
This section describes disaster recovery using Recovery Manager, and using operating system utilities.
The following scenario assumes:
Note: It is highly advisable to back up the database immediately after opening the database reset logs, since all previous backups are invalidated. (This is not shown in the example.)
Note also that the SET UNTIL command is used in case the database structure has changed in the most recent backups, and you wish to recover to that point in time. In this way Recovery Manager restores the database to the same structure the database had at the specified time.
Before You Begin: Before beginning the database restore, you must:
The archive logs up to the logseq number being restored must be cataloged in the recovery catalog, or Recovery Manager will not know where to find them.
If you resync the recovery catalog frequently, and have an up-to-date copy from which you have restored, there should not be many archive logs that need cataloging.
What the Sample Script Does: The following script restores and recovers the database to the most recently available archived log, which is log 124 thread 1. It does the following:
If volume names have changed you must use the statement SET NEWNAME FOR ... before the restore, then perform a switch after the restore (to update the control file with the datafiles' new locations).
Recovery Manager will complete the recovery when it reaches the log sequence number specified.
Note: Only complete the following step if you are certain there are no other archived logs which can be applied.
Restore/Recover Sample Script:
The DBA starts up Server Manager as follows:
SVRMGRL> connect scott/tiger as sysdba Connected.
SVRMGRL> startup nomount restrict
The DBA then starts up Recovery Manager and runs the script.
Note: The user specified in the target parameter must have SYSDBA privilege.
rman target scott/tiger@node1 rcvcat rman/rman@rcat run { set until logseq 124 thread 1; allocate channel t1 type 'SBT_TAPE' connect 'internal/knl@node1'; allocate channel t2 type 'SBT_TAPE' connect 'internal/knl@node1'; allocate channel t3 type 'SBT_TAPE' connect 'internal/knl@node2'; allocate channel t4 type 'SBT_TAPE' connect 'internal/knl@node2'; allocate channel d1 type disk; restore controlfile to '/dev/vgd_1_0/rlvt5'; replicate controlfile from '/dev/vgd_1_0/rlvt5'; sql 'alter database mount'; catalog archivelog '/oracle/db_files/node1/arch/arch_1_123.rdo'; catalog archivelog '/oracle/db_files/node1/arch/arch_1_124.rdo'; restore (database); recover database; sql 'alter database open resetlogs'; }
Use the following procedure.
The following command is an example:
RECOVER DATABASE USING BACKUP CONTROLFILE UNTIL CANCEL
If the suggested archive log is not in the archive directory, specify where the file can be found. If redo information is needed for a thread and a file name is not suggested, try using archive log files for the thread in question.
Note: If any distributed database actions are used, check to see whether your recovery procedures require coordinated distributed database recovery. Otherwise, you may cause logical corruption to the distributed data.
The goal of the parallel recovery feature is to use compute and I/O parallelism to reduce the elapsed time required to perform crash recovery, single-instance recovery, or media recovery. Parallel recovery is most effective at reducing recovery time when several datafiles on several disks are being recovered concurrently.
With Recovery Manager's RESTORE and RECOVER commands Oracle can automatically parallelize all three stages of recovery.
Restoring Data Files: When restoring data files, the number of channels you allocate in the Recovery Manager recover script effectively sets the parallelism with which Recovery Manager will operate. For example, if you allocate 5 channels, you can have up to 5 parallel streams restoring data files.
Applying Incremental Backups: Similarly, when you are applying incremental backups, the number of channels you have allocated determines the potential parallelism.
Applying Redo Logs: Oracle applies the redo logs in parallel, as determined by the RECOVERY_PARALLELISM parameter.
The RECOVERY_PARALLELISM initialization parameter specifies the number of redo application server processes that participate in instance or media recovery. One process reads the log files sequentially and dispatches redo information to several recovery processes, which apply the changes from the log files to the datafiles. A value of 0 or 1 indicates that recovery is to be performed serially by one process. The value of this parameter cannot exceed the value of the PARALLEL_MAX_SERVERS parameter.
You can parallelize instance and media recovery in two ways:
The Oracle Server can use one process to read the log files sequentially and dispatch redo information to several recovery processes to apply the changes from the log files to the datafiles. The recovery processes are started automatically by Oracle, so there is no need to use more than one session to perform recovery.
The RECOVERY_PARALLELISM initialization parameter specifies the number of redo application server processes that participate in instance or media recovery. One process reads the log files sequentially and dispatches redo information to several recovery processes, which apply the changes from the log files to the datafiles. A value of 0 or 1 indicates that recovery is to be performed serially by one process. The value of this parameter cannot exceed the value of the PARALLEL_MAX_SERVERS parameter.
When you use the RECOVER command to parallelize instance and media recovery, the allocation of recovery processes to instances is operating system specific. The DEGREE keyword of the PARALLEL clause can either signify the number of processes on each instance of a parallel server or the number of processes to spread across all instances.